标签: scrapy

Scrapy利器:构建强大爬虫,轻松获取所需数据!
数据采集这活儿吧,讲究的是持久战。代码写完只是开始,调试优化才是重点。不过有了Scrapy这神器,爬虫开发效率蹭蹭往上涨,剩下的就是跟反爬斗智斗勇了。

Scrapy 爬取 5 秒盾站点,速度可以这么快!
一、前言介绍
怀揣着对技术的热爱,迫不及待要与大家分享一场关于 Scrapy 爬虫的技术奇遇。在这个数字化飞速发展的时代,我们时刻面临新的技术挑战。在今天的故事中,我……
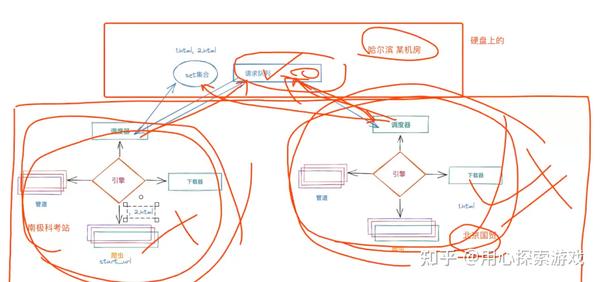
Redis+Scrapy 实现分布式爬虫
分布式和普通爬虫的区别在于原本的一个任务分成了多个任务,由多台机器去跑。
原本 scrapy 是在自己的调度器中用 set() 去重,但这时候是在多个机器进行,就需要共用一个……
Scrapy分布式爬虫自动去重原理
分布式爬虫和普通爬虫区别就是原本一件事一个人干,现在一件事分给几个人干。通过多 IP /机器对同一个目标进行爬取,难点在于如何分配任务,如果一个 URL 已经被其中一个……
feapder:一款能取代 Scrapy 的爬虫框架
1. 前言
众所周知,Python 最流行的爬虫框架是 Scrapy,它主要用于爬取网站结构性数据
今天推荐一款更加简单、轻量级,且功能强大的爬虫框架:feapder
2. 介绍及安装
和……

Python爬虫开发选型——Scrapy
一、序言 随着国内大大小小企业数智化转型不断深入,最大程度地满足业务需求,最佳手段是靠数据决策、智能流程来完成。伴随着 GPT5 横空问世,已是企业长久可持续发……
scrapy通用爬虫及反爬技巧
一、通用爬虫
通用爬虫一般有以下通用特性:
爬取大量(一般来说是无限)的网站而不是特定的一些网站。
不会将整个网站都爬取完毕,因为这十分不实际(或者说是不可能)完成的……

scrapy 爬虫中间件学习笔记:download middlerware用法
Scrapy中间件是一个处理Scrapy请求和响应的机制。中间件可以在请求或响应被Scrapy引擎处理之前或之后对其进行修改或操作,用于实现诸如缓存、代理、用户代理等功能。
Scr……

图形化scrapy爬虫控制台Gerapy安装与配置教程
1.安装依赖 #pip install - r requirements.txt
scrapy
scrapyd
gerapy
django
jinja2 pywin32 # windows需要安装,linux不需要 2. 开启scrapyd $scrapyd 开……

scrapy框架基本定义与命令介绍
一、scrapy介绍及其工作流程
1.1 什么是scrapy
scrapy是一个爬虫中封装好的明星框架,诞生之初是为了页面的抓取,之后进一步扩展可应用于获取 api所返回的数据或者通用的……

Scrapy 使用代理IP并将输出保存到 jsonline
1、使用 scrapy 中间件,您需要在 settings.py 中启用 HttpProxyMiddleware,例如: DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.Http……

Scrapy数据爬取+Django+PyEcharts实现可视化大屏(附源码)
小伙伴问我有没有基于Django的可视化大屏,小F就顺手找了一下。
于是便在GitHub上发现了一个不错的实战项目,基于qunaer长沙景点数据。
还是作者最近几天刚更新的,保真~……

Scrapy框架结合selenium获取动态加载数据
一、新建一个Scrapy项目wangyi,进入该项目,创建wangyipc爬虫文件 scrapy startproject wangyi
cd wangyi
scrapy genspider wangyipc www.xxx.com 二、修改settings……

Scrapy爬虫框架爬取图片示例
一、新建一个tupian爬虫项目 scrapy startproject tupian 二、进入到tupian项目,新建一个image爬虫文件 cd tupian
scrapy genspider image www.xxx.com 三、修改配……

scrapy爬虫开发8步标准流程
Scrapy爬虫的标准流程一般包括以下几个步骤:
1、明确需求和目标网站的结构,确定需要爬取的数据以及爬取规则。
2、创建一个Scrapy项目,使用命令行工具创建一个新的Scra……

Scrapy爬虫框架安装与原理图解介绍
Scrapy爬虫框架也是爬虫项目常用的框架之一,Scrapy通过Python 编写,台式一个快速、高层次的屏幕抓取和网页抓取框架,Scrapy框架的用途广泛,可以用于数据挖掘、监测和……
Scrapy中间件采集HTTPS网站失败的原因
Scrapy 是一个基于 Python 的网络抓取框架,可以帮助开发人员从网站中快速有效地提取数据。Scrapy 的一个显著优势是可以通过中间件来定制和优化抓取过程。中间件是一种插……

Scrapy框架教程:深度爬取并持久化保存图片
一、新建一个Scrapy项目daimg scrapy startproject daimg 二、进入该项目并创建爬虫文件daimgpc cd daimg
scrapy genspider daimgpc www.xxx.com 三、修改配置文件……

Scrapy框架教程:POST请求实现案例
一、创建一个Scrapy项目fanyi,并进入该项目创建,fanyipc爬虫文件 scrapy startproject fanyi
cd fanyi
scrapy genspider example example.com 二、修改配置文件set……

Scrapy爬虫学习笔记:安装及VS CODE配置
一、环境搭建
1. 本文运行环境
代码编辑器:Visual Studio Code: 1.76.2(推荐)
操作系统: Windows 11 专业版 22H2
Python:3.10.7
2. 安装虚拟环境 # 安装虚拟环境模……

scrapy中的数据采集日志管理
不同于原生爬虫代码的是,scrapy是一个相对较成熟的框架,所以并不能直接去执行某一个python文件来执行采集任务,而是要通过脚本命令来实现项目的启动。
一、scrapy的步……

Scrapy框架结合百度AI实现文本处理
一、进入百度AI首页,点击右上角的控制台 二、点击左上角的三条杠,选择产品服务,选择自然语言处理 三、点击应用列表,点击创建引用 四、选中我们要进行的文章分类和……

python爬虫学习笔记:第一个Scrapy爬虫框架
一、安装scrapy库文件 pip install scrapy 二、创建项目
1、在Pycharm的终端里面运行 scrapy startproject 项目名称 2、进入到创建的目录,并执行下面代码 cd kjp……

使用scrapy-redis爬取豆果美食分类及详情页数据
使用scrapy-redis抓取豆果美食分类,以及详情页数据
数据存储:MySQL
1. 创建项目
于终端输入指令:scrapy startproject "项目名"
使用命令cd进入创建项目的spiders文件……