Redis+Scrapy 实现分布式爬虫
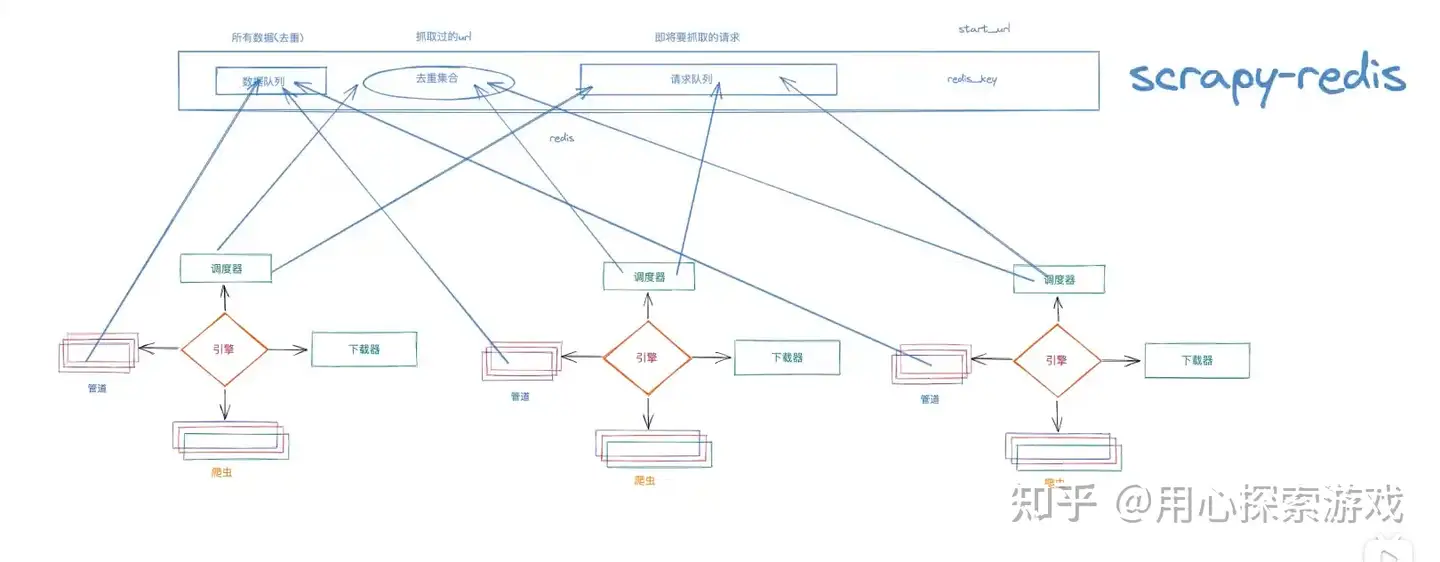
分布式和普通爬虫的区别在于原本的一个任务分成了多个任务,由多台机器去跑。
原本 scrapy 是在自己的调度器中用 set() 去重,但这时候是在多个机器进行,就需要共用一个东西进行去重,不然这边爬过了,那边又爬一遍。
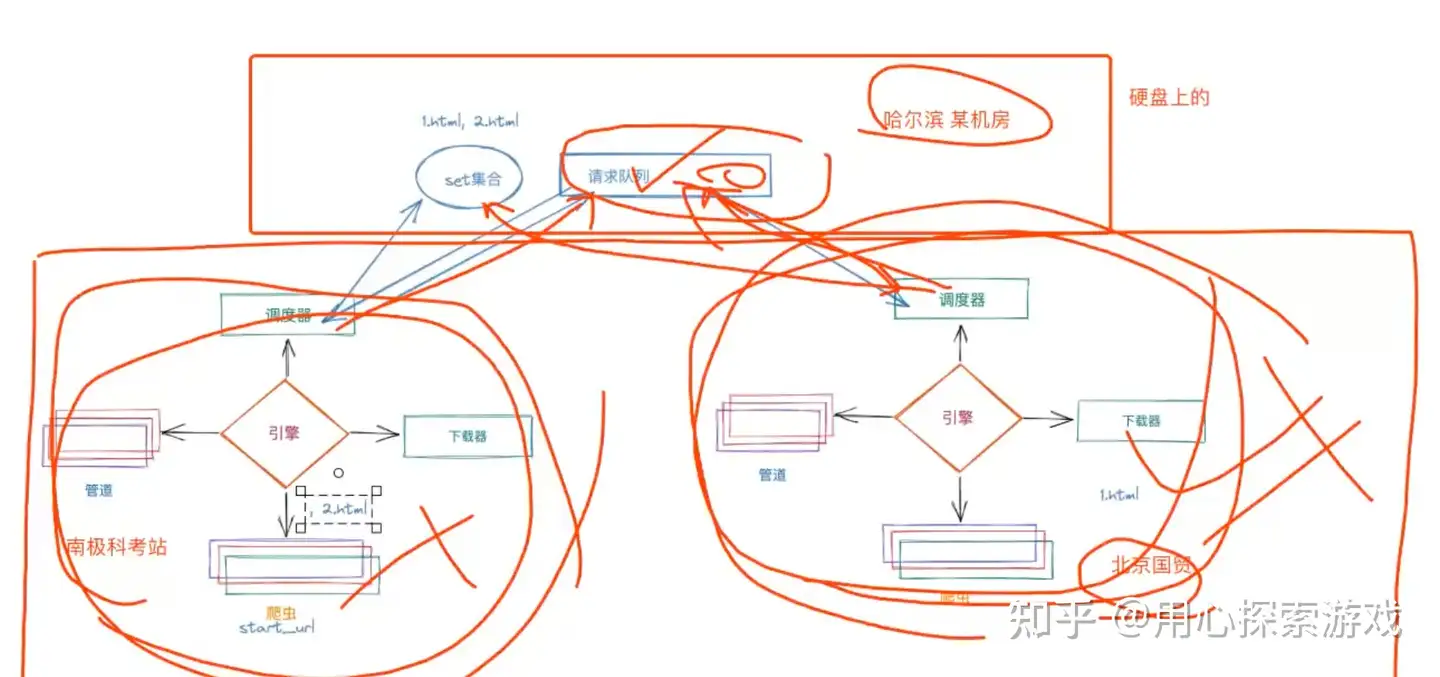
整个原理简单来说就是利用 Redis 实现把多个爬虫的 set和请求队列合为一体,Redis 开启远程连接,其他机器通过 set 查重并把合格的 URL 存进另一个集合(充当请求队列)。到这里同时也就实现了断点续爬,如果爬虫因某些原因中断了,但此时在 Redis 中的数据并没有损失,爬过的 URL 已经记录下来了,请求队列的数据也还在
解析完数据后再把数据传到 Redis 存储
如何开始爬虫?主要是 URL 来源和数据的去向发生改变,以及无需在代码中判断数据是否重复,全部去重由 scrapy_redis完成
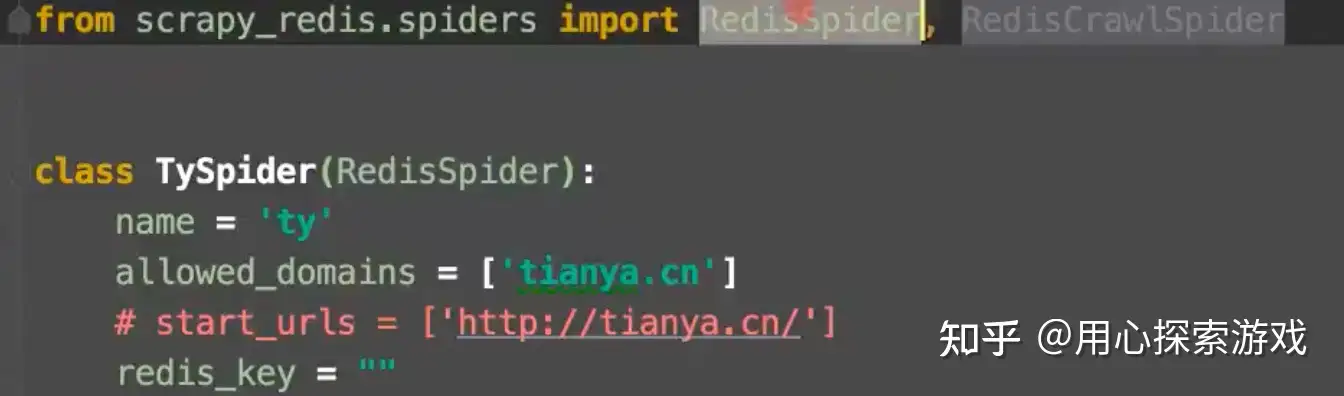
1、start_urls换成 redis_key。因为 start_urls是由它的start_request调用并 yield请求的,但它会在请求中设置dont_filter = True ,也就是说 start_urls里的 URL 会绕过基于 set()集合的去重,必定被爬取。那么多个机器就会重复请求 start_urls里的 URL,scrapy_redis里存放了一个 redis_key,它会把 redis_key放到请求队列里,现在变成了谁抢到 redis_key谁发起第一个请求。
2、类继承的scrapy.Spider换成 scrapy_redis.Spider里的 RedisSpider,如果是 crawlSpider 就用 RedisCrawlSpider
3、设置 scrapy_redis的 pipeline

4、在 settings 中配置
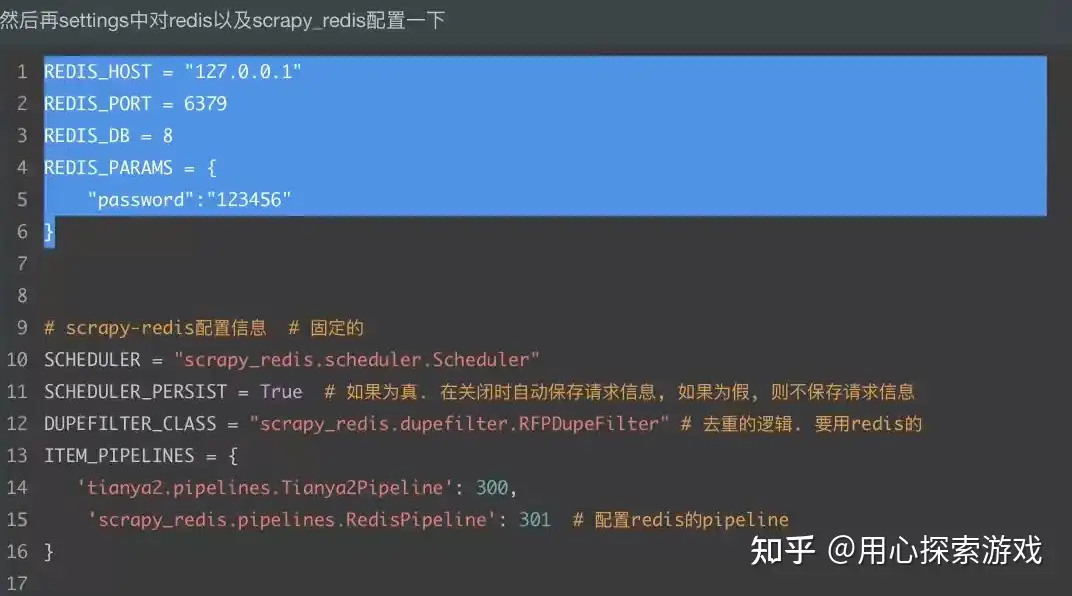
5、此时可以启动爬虫,这时爬虫会等待,因为它们没有 start_urls,而是使用了redis_key。要让爬虫运行起来,就要在第三个地方连上 Redis,然后 select 对应的数据库,如这里是 select 8。我们redis_key的值是"ty_start_url",所以我们在数据库中写入 ty_start_url,并将起始页作为它的值

然后爬虫就会开始运行,完毕!
补充:一般数据去重有四个方案

4是最好的,在 setting 中改好下面配置就行了
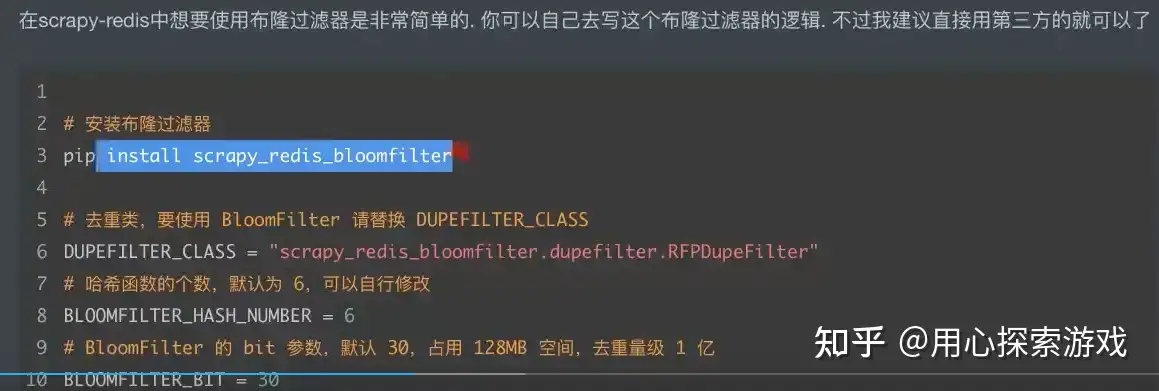
总逻辑图如下