AI大语言模型构建流程及预训练步骤
01.确定需求大小
在构建大语言模型的前期准备中,基础设施是最为重要的,GPU的型号以及数据直接关系到模型的训练质量和训练时间。例如:使用单个V100的GPU训练具有1750亿个参数的GPT-3将需要约288年,那就更不用提现在动辄万亿参数的大模型。好在随着A100和H100更强算力资源的推出,大模型的训练速度被大大加快。
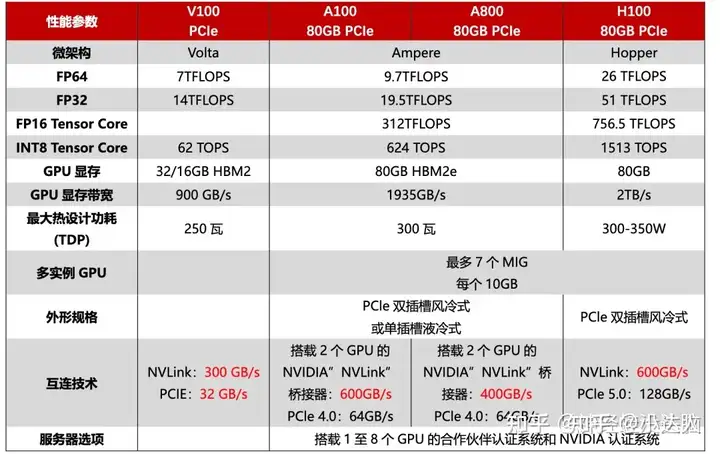
但是即便是单GPU的算力提升,训练超级规模的大语言模型也并不是一件容易的事情,这是因为:
a)GPU内存容量是有限的,使得即使在多GPU服务器上也无法适合大型模型
b)所需的计算操作的数量可能导致不切实际的长训练时间。
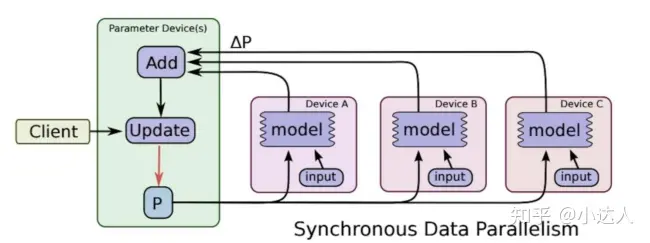
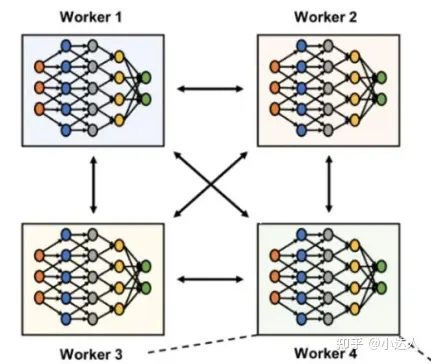
后来,各种模型并行性技术以及多机多卡的分布式训练部分解决了这两个挑战。
使用数据并行性,每个工作人员都有一个完整模型的副本,输入数据集被分割,工作人员定期聚合他们的梯度,以确保所有工作人员都看到权重的一致版本。对于不适合单个GPU的大模型,数据并行性可以在较小的模型碎片上使用。
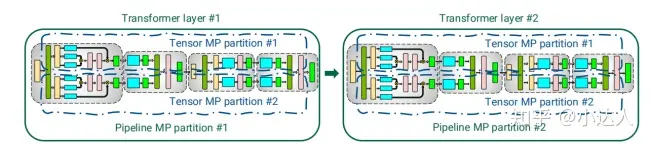
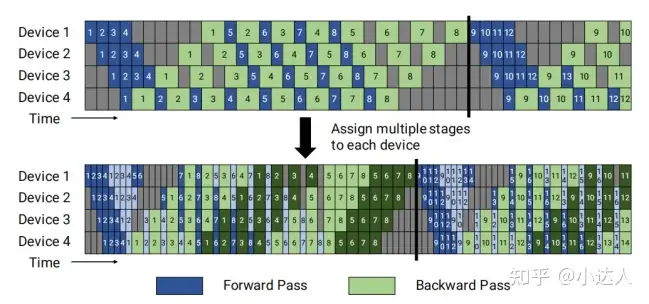
当使用相同变压器块的模型时,每个设备可以分配相同数量的变压器层。一个批被分割成更小的微批;然后在微批次之间通过流水线执行。为了精确地保留严格的优化器语义,技术人员引入了周期性的管道刷新,以便优化器步骤能够跨设备同步。
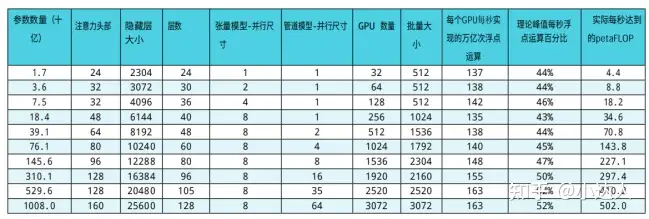
在大模型开始训练之前,我们可以考虑到这些吞吐量,估计出进行端到端训练所需的总时间。
端到端的训练时间计算公式如下:

我们以P=1750亿个参数的GPT-3模型为例。
该模型在T=3000亿个Tokens上进行了训练。在n= 1024 A100图形处理器上,使用批量大小为1536,实现了X=140兆浮点运算每秒每个GPU。因此,训练这个模型所需的时间是34天。对于1万亿个参数模型,我们假设端到端训练需要4500亿个Tokens。使用3072个A100 GPU,我们可以实现每个GPU的吞吐量为163兆浮点运算每秒每个GPU,所以训练时间为84天。事实上,技术进步能够给我们带来的好处是,变量X的提高使得我们训练模型所需要的时间正在逐步减少,因此对于搭建自有的大模型来说,训练多大的规模参数就需要有多大规模的算力。
02.数据收集
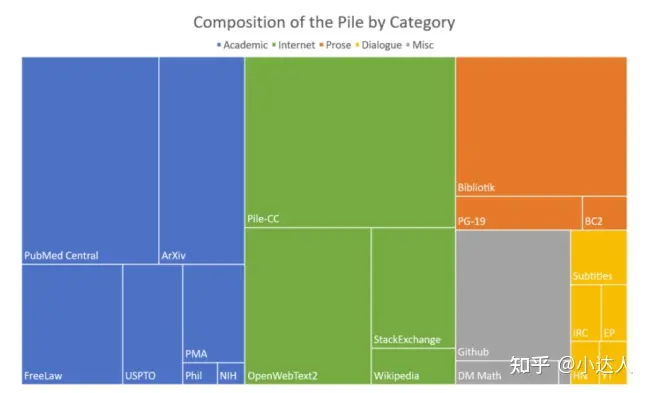
对于初代大模型来说,数据收集以及后续的处理是一件非常繁琐且棘手的事情,在这一过程中需要面临诸多的问题,比如数据许可,数据集的特征和覆盖率,数据预处理的充分性,如何解决数据集偏差,如何解决数据集公平性,不同国家数据集的差异,数据隐私,数据安全等等。
初代大模型的推出是具有跨时代的意义,这不仅仅是让人们充分利用到大语言模型的便利性,也为更多大语言的推出铺平了道路,例如:ChatGPT训练了几乎所有能在公开渠道找到的数据,包括全部的推特数据(事实上,今年马斯克已经限制了推特API的采集数量,所以后续大模型再想利用全部的推特数据来完成训练,几乎已经不可能了)。这个对于后续的大模型开发提供了便利,一方面后续的大语言模型可以借助ChatGPT更好的完成数据集收集任务,另一方面ChatGPT成功的经验也为后续其他大模型的数据收集提供了经验。
1.公开的未标记的数据
公开的数据获取方式有很多,ChatGPT的数据获取途径包含了维基百科、BookCorpus,国内的就可以利用微博、百度百科、贴吧、知乎等等收集预训练集。
2.开源的数据集
随着大模型如火如荼的进行,开源的数据集已经越来越多,例如以下等等,当然也可以利用谷歌的Dataset Search进行搜索。
OSCAR(https://oscar-corpus.com)
The Pile(https://pile.eleuther.ai)
PaperswithCode(https://paperswithcode.com)
Hugging Face(https://huggingface.co)
Github(https://github.com)
飞桨(https://aistudio.baidu.com)
3.爬虫收集
在合规的前提下,爬虫收集也可以定向收集到优质的数据集。
这个过程通常与数据增强结合使用,这有助于减轻过度拟合,提高模型的鲁棒性。在进行混合时,需要为每个样本或特征分配一个权重,这些权重可以是固定的,也可以是随机的,权重的选择方式取决于混合策略和具体任务。例如,对于某些图像分类任务,更高的混合比例可能有助于提高模型的泛化能力,而对于其他任务,适度的混合比例可能就足够了。
混合时也要考虑数据的大小和多样性,如果你的数据集非常庞大,多样性强,那么可以考虑使用较低的混合比例,因为你已经有足够的数据来训练模型。但是如果数据集相对较小,多样性低,增加混合比例可能有助于增加样本数量,减轻过拟合。
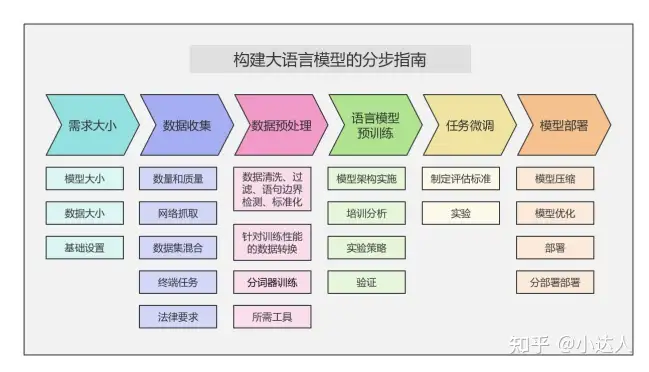
03.数据集预处理
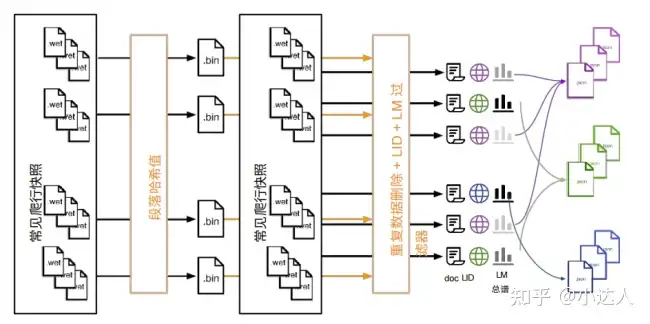
1.数据清洗、过滤、语句边界检测、标准化
大语言模型具有采样效率高的特点,这意味着如果输入模型的数据充满拼写错误的单词、性质粗俗(从网络论坛/聊天室中提取的未经审查的数据通常就是这种情况)、包含大量目标语言之外的其他语言,或者具有不受欢迎的恶作剧特征,那么大模型最终的效果也可想而知。基于此,在对大模型进行训练之前,需要对收集到的数据进行预处理操作,这其中就包含数据清洗、过滤、语句边界检测、标准化。
2.针对训练性能的数据转换
训练机器学习模型时需要对原始数据进行各种处理和转换,以提高模型的性能和泛化能力。这些数据转换的目标是使训练数据更适合于模型的学习和泛化,以及减少模型的过拟风险。例如特征缩放、特征工程、数据清洗、特征选择、数据增强、标签平滑、数据分割等等。
3.分词器训练
分词器是自然语言处理(NLP)中的重要工具,用于将连续的文本序列分解成单个的词汇或标记。分词器的训练是为了使其能够理解不同语言和领域中的文本,并能够准确地划分词汇。下面是关于分词器训练的一些基本知识:
分词器一般分为两种,一种是基于规则的分词器,这些分词器使用预定义的规则来划分文本,例如在空格或标点符号处进行划分。它们通常适用于某些语言的简单分词任务。另一种是基于统计的分词器,这些分词器依赖于大量的文本数据来学习词汇的频率和上下文信息,然后根据统计信息来进行分词。它们通常更适用于复杂的自然语言处理任务。
一般而言,我们构建分词器可以通过sentencepiece(https://github.com/huggingface/tokenizers/issues/203)或者tokenizers(https://huggingface.co/docs/tokenizers/index)框架来构建。
04.大语言模型预训练
在上一篇文章的第一部分,我们大概聊了一下模型的大小与GPU性能对于大模型的影响以及面临的问题,我们也提到了数据并行和模型并行的方法。
使用数据并行性,每个工作人员都有一个完整模型的副本,输入数据集被分割,工作人员定期聚合他们的梯度,以确保所有工作人员都看到权重的一致版本。对于不适合单个GPU的大型模型,数据并行性可以在较小的模型碎片上使用。
通过模型并行性,模型的图层将在多个设备之间共享。当使用相同变压器块的模型时,每个设备可以分配相同数量的变压器层。一个批被分割成更小的微批;然后在微批次之间通过流水线执行。为了精确地保留严格的优化器语义,技术人员引入了周期性的管道刷新,以便优化器步骤能够跨设备同步。
实际上,大模型预训练的过程中需要注意的问题远不是这么简单。分布式训练能够解决小模型的训练问题,但是随着模型的增大,训练数据集规模的增长,数据并行就会出现局限性。当训练资源扩大到一定规模时,就会出现通信瓶颈,计算资源的边际效应显现,增加资源也没办法进行加速,这就是常说的“通信墙”。
除此之外,大模型训练可能还会遇到性能墙的困扰。性能墙是指在某个特定任务或计算资源上,模型的性能无法继续有效提升的情况。当模型接近性能墙时,增加更多的计算资源或数据量可能不会显著改善模型的性能,因为模型已经达到了某种极限或瓶颈。
性能墙通常表现为以下几种情况:
1)训练时间增长:随着模型规模的增大,训练时间也呈现出显著的增长趋势。这是因为更大的模型需要更多的计算资源和时间来收敛,但性能提升可能会递减,最终趋于停滞。
2)资源利用不高:增加更多的计算资源(例如,GPU或TPU)可能会减少训练时间,但利用率不高,因为模型可能无法有效地利用所有资源来提升性能。
那么,什么样的标准才算大模型训练成功呢?
一般我们会通过定量分析和定性分析来回答这个问题。
首先定量分析,我们会观察大模型的训练损失,训练损失的减少表明模型正在学习并拟合训练数据。其次我们会检查大模型的性能指标,对于分类任务,常用的指标包括准确率、精确度、召回率、F1 分数和 ROC-AUC。对于回归任务,常用的指标包括均方误差(MSE)、平均绝对误差(MAE)和 R 平方。
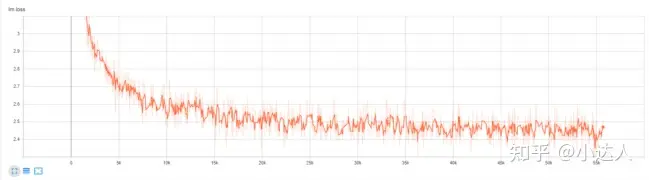
其次是定性分析,我们通过合并检查点,将多个保存的模型检查点合并为一个单一的统一检查点文件。一旦合并了检查点或选择了特定检查点,我们可以从该检查点加载模型,然后,使用加载的模型生成文本。这时候我们就需要检查生成句子的连贯性、语法、相关性、多样性等,评估句子的生成质量。
另外,我们也通过验证集和测试集的评估来观察大模型的表现,一来观察大模型在处理验证集和测试集时的各项指标,二来观察大模型是否有过拟合的现象出现。
05.任务微调
在大模型进行预训练之后,往往需要对其进行实验和微调处理,实验的作用是检验大模型是否训练成功,这个我们在上一篇文章中已经进行了说明。如果实验结果证明大模型的训练是成功的,那么接下来我们就需要进行微调处理。
微调处理的好处是可以对大模型有针对性的做出训练,例如大模型的侧重点是在情感分析还是在机器翻译?又或者是文本分类?通过微调之后大模型在垂直领域的适应性将会更强,准确率更高。这一过程中,我们通常称之为价值观的对齐,目的就是提高模型的性能、适应性和效率,充分利用大模型的通用知识,并使其更好地适应不同的任务和领域。
大模型的微调方法有多种多样,例如Houlsby N 的 Adapter Tuning,微软的 LoRA,斯坦福的 Prefix-Tuning,谷歌的 Prompt Tuning,清华的 P-tuning v2。
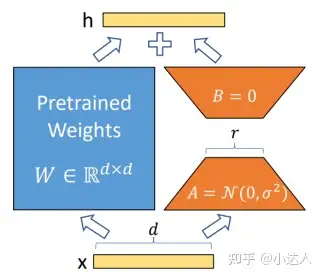
以LoRA为例,LoRA的本质是认为预训练模型拥有极小的内在维度,即存在一个极低维度的参数A和B,微调它和在全参数空间中微调能起到相同的效果。更加专业的解释就是:训练的时候固定预训练语言模型的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与预训练语言模型的参数叠加。用随机高斯分布初始化A,用0矩阵初始化B。这样能保证训练开始时,新增的通路BA=0,从而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
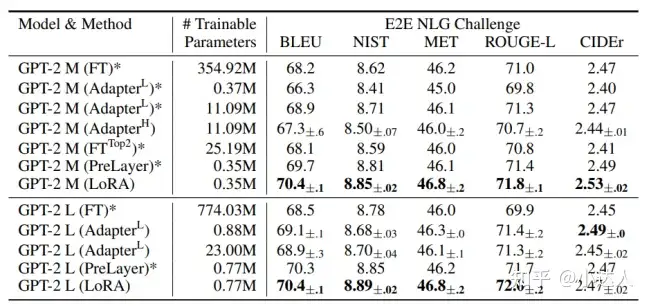
基于LoRA优秀的微调能力,后来者QLoRA、AdaLoRA和Alpaca-LoRA的技术衍生,进一步加快的微调过程的时间,缩减了成本。QLoRA的论文中这么写道:QLoRA能够将对一个拥有65亿参数的模型进行微调所需的平均内存要求从超过780GB的GPU内存降低到不到48GB,而且与一个16位完全微调的基线相比,不会降低运行时性能或预测性能。这标志着在LLM微调的可访问性方面取得了显著进展:现在,迄今为止最大的公开可用模型可以在单个GPU上进行微调。
使用QLoRA,我们训练了Guanaco系列的模型,第二优的模型在Vicuna基准测试中达到了ChatGPT性能水平的97.8%,而在单个消费级GPU上训练时间不到12小时;而使用单个专业GPU在24小时内,我们的最大模型达到了99.3%,基本上追赶上了Vicuna基准测试中的ChatGPT。
在部署时,我们最小的Guanaco模型(7亿参数)仅需要5GB内存,比一个拥有26GB参数的Alpaca模型在Vicuna基准测试中的表现高出20个百分点以上。
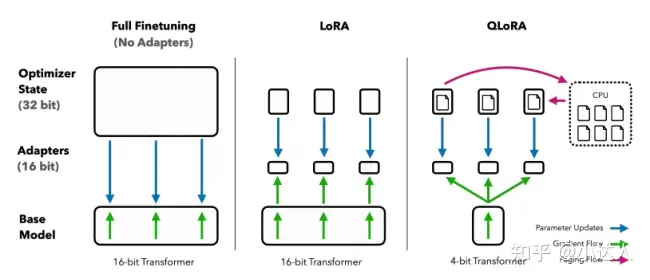
后来的Alpaca-LoRA更是离谱,已经有人使用一块 RTX 4090 显卡,只用 5 个小时就训练了一个与 Alpaca 水平相当的模型,将这类模型对算力的需求降到了消费级,还能获得和全模型微调类似的效果。
Alpaca-LoRA Github地址:https://github.com/tloen/alpaca-lora
06.部署
训练过程中需要大量的GPU资源,模型的部署过程中同样需要,以175B的模型为例,不压缩模型的情况下部署需要650GB的内存,这个时候,我们就可以通过模型的缩减和压缩或者采用分布式部署的方式来减轻我们的部署压力。







