机器学习用numpy撰写KNN算法 并预测价格走势
KNN算法简介
KNN 算法实际上是一句中国谚语智慧的体现:“物以类聚,人以群分”,是一种聚类分析的方法,也是目前最简单的无监督类学习方法。
我们在日常生活中有这样的推论,身边朋友都爱喝酒的人,可能是爱喝酒的人;身边朋友都认为身边朋友都爱喝酒的人可能是爱喝酒的人的人,可能是认为身边朋友都爱喝酒的人可能是爱喝酒的人的人。
基于这样的逻辑,如果现在我们有几个点,分布在二维平面上:
现在突然出现了一个这样颜色不明的点(这明明就是黑的)
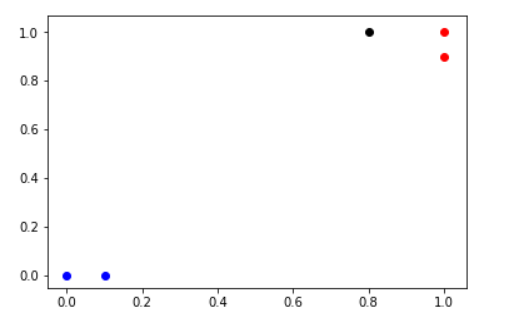
很自然的我们下意识的觉得这个点
是蓝的!
好好好,别动手有话好商量,事实上正常人肯定觉得这个点颜色应该是红色的。

这种聚类思想可以运用到很多分类问题中,比如股票价格未来走势的预测(醒醒吧,也就这么顺口一说,要是准确率高我还会在这里写文章吗?)
这种方法的严谨的数学表达是:首先确定距离的度量方法,事实上在数学上有很多种距离的度量方法,比如切比雪夫距离,欧氏距离,曼哈顿距离,这些距离实际上对应的是一个叫做范数的数学概念,鉴于这篇文章不是数学讲堂,同时还指望着流量点击养家糊口,就不一一叙述了。这里我们给出对欧式距离(L2 范数)的计算方法
对于 x ∈ Rn,存在 x 的集合 X,x1、x2 ∈ X,定义

诶嘿,是不是突然发现很熟悉,然后读者们可能就要开始骂了,故弄什么玄虚,这不就是 n 维空间内点的直线距离吗,没有错,L2 范数对应的就是点在空间内部的直线距离。根据分类的标的不同,我们使用不同的距离度量方法来适应样本的独特性质,不过一般情况下使用直线距离就足够了,毕竟老夫也不是什么恶魔,况且 L2 范数已经具有相当良好的数学性质,比如连续,可导…跑题了,咳……
既然刚刚已经明确了距离的概念,这样当我们拥有一个非常完整的样本的情况下,特征完整标签明确。当我们想对一个新来的点或者一些样本进行分类的时候,我们可以逐一计算这个(些)新来的样本和已知的样本点之间的距离,然后取离这个点最近的 K 个已知样本。统计一下这些已知样本点对应标签的数量,选取出现次数最多的标签作为新来样本点的分类。
当然这个 K 参数是自行选择的,有一个小技巧是,K 参数尽量避免成为标签集合数量的倍数,原因试一试就知道了。
KNN 算法的优点在于:
KNN算法的缺点在于:
KNN算法实战
1.选取标的:中证 800
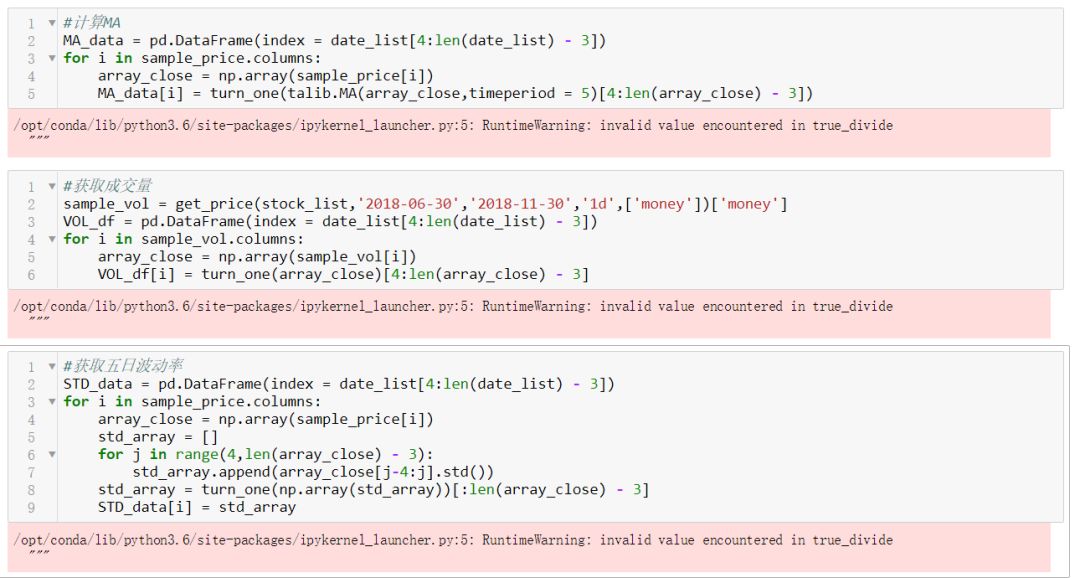
2.选取特征:5 日MA,5 日价格波动率,日内成交额
3.分类目标:当日获取数据后 3 日收益率,为正标注为 1,为负标注为-1,0 变动标注为 0
4.特征处理:对量纲不同的数据进行归一化

5.算法实现:导入必要库
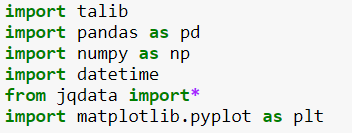
获取价格,计算三日收益率并标注数据
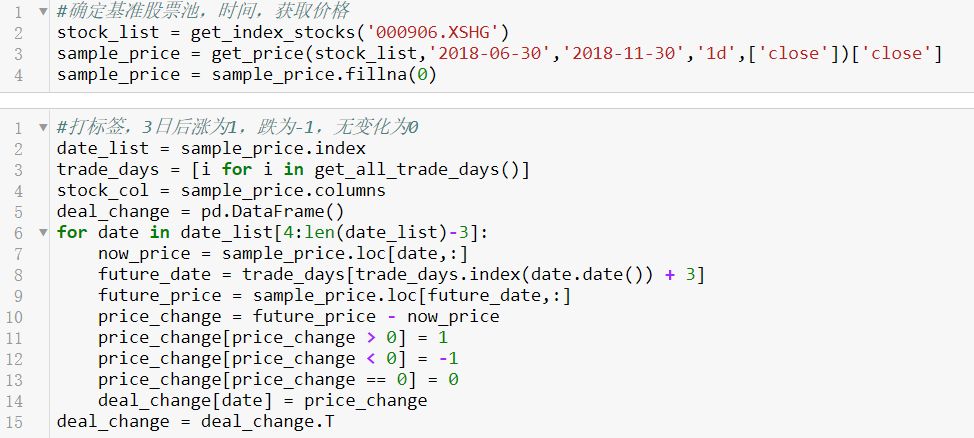
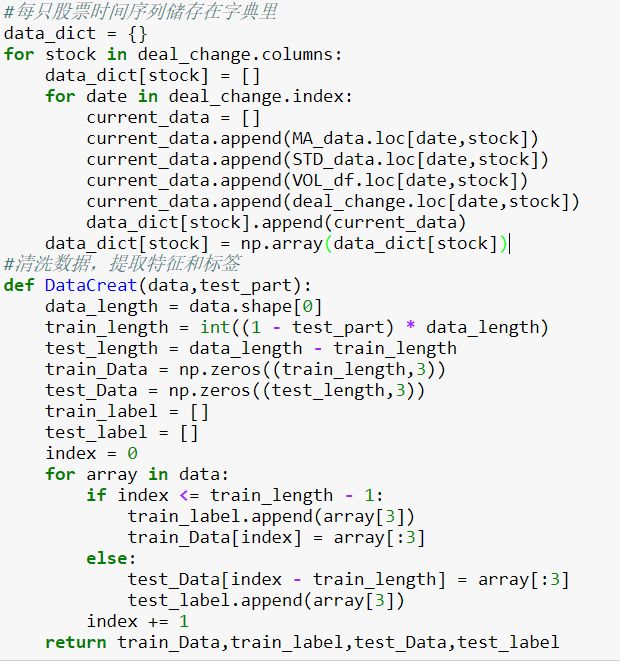
提取特征值并归一化
分离测试样本与训练样本
定义计算L2范数方法

预测并评估性能

6.训练结果:
最终全市场训练准确率在各个参数下,均值收敛到53.6%,虽然一般但是已经好过随机选择很多了
值得一提的是……emmmm,有只股票的预测准确率居然达到了100%......这显然就是样本数量取少了碰巧蒙上了,但是不要紧,至少这个方法会了就行了。
作者:刘建涛




