基于Megatron-Core稀疏大模型训练工具:阿里云MoE最佳实践
作者:李鹏1,颜子杰2,王明1,颜海强1,刘振寰2,黄俊1
单位:阿里云人工智能平台PAI1,NVIDIA DevTech Team2
01
概述
随着大模型技术的不断发展,模型结构和参数量级快速演化。大模型技术的应用层出不穷。大模型展现惊人效果,但训练和推理成本高,一直是巨大挑战。模型稀疏化能降低计算和存储消耗。近期以Mixtral为代表的MoE(多专家混合)大模型证明了稀疏MoE技术能大幅降低计算量、提升推理速度,模型效果甚至超过同规模稠密模型。阿里云PAI和NVIDIA团队深入合作,基于Megatron-Core MoE框架,解决了MoE大模型训练落地时会遇到的可拓展性、易用性、功能性以及收敛精度等核心问题,在下游任务上取得了很好的模型效果。PAI团队将上述MoE训练框架和技术与阿里云AI平台产品深度整合,使云上大模型用户能方便地进行MoE大模型的训练和部署。
02
基于 Megatron-Core 的 MoE 训练工具链
这一章节中,我们从MoE算法介绍,Megatron-Core MoE训练框架、以及云平台工具三个方面了解支撑MoE落地背后的基础能力。
MoE 算法介绍
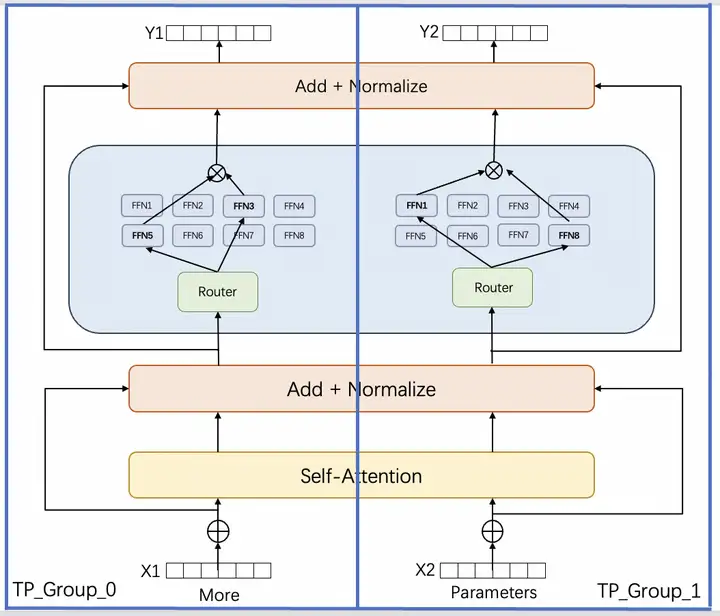
MoE的全称是Mixture of Experts,其中的Expert对应的是Transfomrer模型的MLP层,在训练的时候从多个MLP中选取一个MLP进行激活 [1](如下图所示)。这意味着模型可以在不增加FLOPs的情况下,通过增加MLP模块的数量来增加模型参数量级,进而提升模型在下游任务上的效果。采用MoE后的稀疏Transformer模型和同等质量(验证集loss以及Zero-shot NLU下游任务性能)的稠密模型相比有较大幅度的训练和推理吞吐性能提升。MoE主要由以下两个关键部分组成:
- 稀疏MoE层: 这些层代替了传统 Transformer模型中的前馈网络 (FFN) 层。MoE层包含若干experts组成,每个experts本身是一个独立的神经网络。在实际应用中这些专家通常是前馈网络 (FFN)。
- Router路由: 这个部分用于决定哪些tokens被发送到哪个专家。例如在下图中,“More”这个tokens可能被发送到第二个专家,而“Parameters”这个tokens被发送到第一个专家。
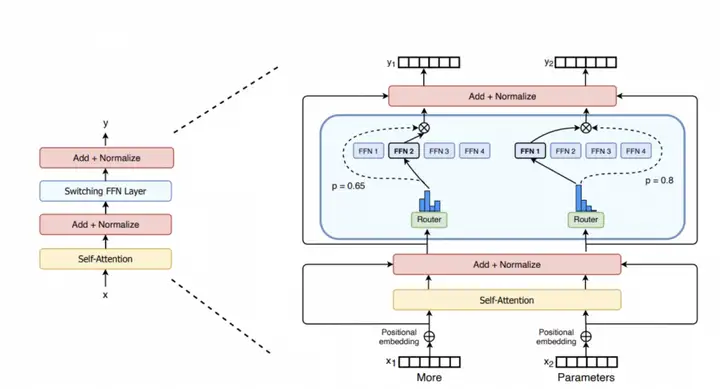
接着我们讨论下MoE中的token负载均衡问题。如上图所示的Top-1 Routing算法,每个输入hidden_states被router分配了4个experts中的1个用于前向推理计算,然后其输出被加权求和汇总后送入Transformer的下一个处理单元。这种路由方式会出现少数受欢迎的experts需要处理很多token,而其他experts仅需处理极少数量的token的情况,这导致处理极少token的那些experts无法获得足够多的信息,从而导致训练效率大幅降低。
为了缓解这种token到expert负载不均衡(Load Imbalancing)的问题,可以引入了一个辅助损失函数,旨在鼓励给予所有专家相同的重要性。这个损失函数确保所有专家接收到大致相等数量的训练样本,从而平衡了专家之间的选择。另外也可以通过drop tokens的方式得到缓解。首先定义一个expert capacity,即为一个expert被分配到的token的容量。如果分配到一个expert的token数超出了一个固定容量,则多余的tokens会被丢掉。这些被丢掉的tokens不参与和experts的矩阵乘运算,直接通过一个残差连接进入到下一个处理单元。如果一个expert没有被分配到其容量上限内的足够多的tokens,则需要采用padding的方式填充到容量上限。
Mixtral-8x7b模型提供了另外一种思路来缓解负载不均衡的问题,其采用的Megablocks [2]论文中提出的dropless moe算法。如下图所示,首先tokens通过router被分配到具体的experts,token到expert的分配关系被存储到expert indices中,分配置信度被存储到Probabilities中。其次根据预先设置好的expert的容量将tokens分组放置,超出容量的tokens被丢掉。接着将分组中的tokens和experts进行批量矩阵乘运算。最后输出结果按照分配置信度进行加权求和(如下左边公式),其分配置信度的计算采用的是normalized softmax(如下右边公式)。
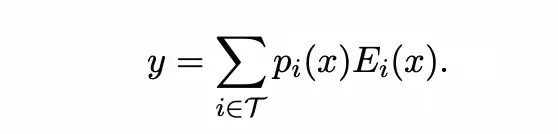
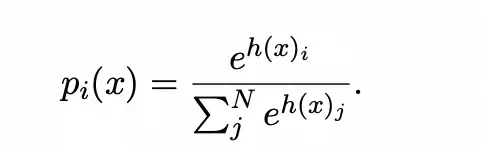
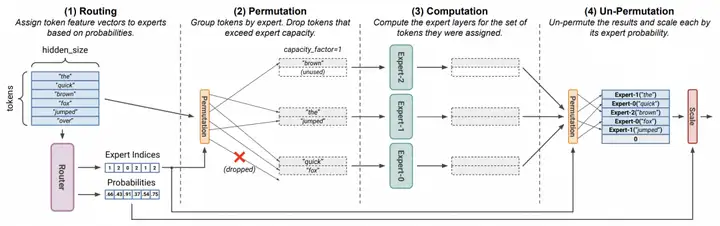
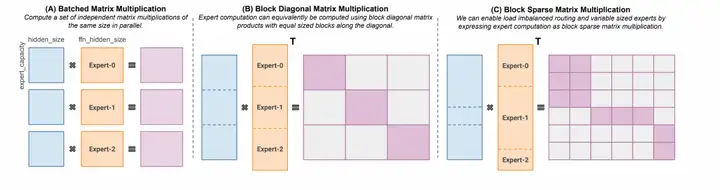
Megablock论文认为这个drop token方案会导致效果下降,于是在此基础上引入块稀疏算子来实现dropless功能。如下图所示,dropable的moe算法在experts之间并行批量矩阵乘(如下图A所示)可以用一种块对角矩阵乘来等价表达(如下图B所示)。Megablock设计了一个新的算子允许变长的输入(如下图C所示),然后输出到一个稀疏对角矩阵上。引入了这个变长输入就意味着不需要drop的方式就能处理超出容量的tokens。类似的,Megatron-Core MoE使用GroupedGEMM解决了多 expert变长输入的问题。
Megatron-Core MoE 训练框架
Megatron-Core是NVIDIA推出的一个成熟且轻量级的大规模LLM训练框架,它包含了训练大规模LLM模型所需的所有关键技术,例如各类模型并行的支持、算子优化、通信优化、显存优化以及FP8低精度训练等。Megatron-Core不仅继承了前代Megatron-LM的优秀特性,还在代码质量、稳定性、功能丰富性和测试覆盖率上进行了全面提升。更重要的是,Megatron-Core在设计上更加解耦和模块化,不仅提高了LLM训练的效率和稳定性,也为二次开发和探索新的LLM架构提供了更大的灵活性。
基于Megatron-Core,研究人员可以在大规模集群上高效地训练各种大型LLM模型,其中也包括对 MoE 模型的探索。MoE的建模方式也带来了参数量的急剧上升、MoE层复杂的通信逻辑、Routing等额外的开销,都给训练框架带来了不小的挑战。其中首当其冲的就是如何在多个GPU间高效的拓展MoE 训练。
在最新发布的Megatron-Core v0.5中,Megatron-Core正式推出了对大规模MoE模型训练的支持,也就是Megatron-Core MoE,涵盖了并行性、路由和负载均衡、性能优化、Token分发机制等多个feature。以下是一些值得关注的特性:
并行性(Parallelism)
Megatron-Core MoE支持专家并行(Expert Parallel),这是一种专门为MoE模型设计的并行方法。在这种并行化策略中,不同的 Rank 负责处理其中一个或多个专家的计算。
此外,Megatron-Core MoE还支持3D并行(Data Parallel, Tensor Parallel, Pipeline Parallel, Sequence Parallel)。对于更大的MoE模型, Megatron-Core MoE也支持将专家并行(EP)与其它的并行DP/TP/PP/SP/Distributed Optimizer结合使用。
未来,Megatron-Core MoE还将支持Context Parallel,以支持更长序列的训练。
Token 分发机制(Token Dispatch Mechanism)
Megatron-Core MoE目前提供了对Dropless MoE的支持(不进行Token丢弃)。即将加入对Token drop MoE的支持。
路由和负载均衡(Router and Load Balancing)
Megatron-Core MoE提供了多种路由类型,包括通用的Top-K router和即将推出的Expert Choice router。
在负载均衡算法方面,支持Sinkhorn(S-BASE)、Z-Loss,以及Load balancing Loss。
Grouped GEMM
Megatron-Core MoE开发了GroupedGEMM来解决多Experts变长输入这一问题。当每个Rank有多个专家时,Megatron-Core MoE利用自CUTLASS 2.8引入的Grouped GEMM特性,将多个局部(可能是较小的)GEMM操作合并为单个GroupedGEMM kernel,能够大幅度提高SM利用率和性能。
同时,Megatron-Core MoE还将部分效率较低的操作替换为优化后的CUDA Kernel,如Sinkhorn、local token permutation/unpermutation等。
即将推出的功能与优化
近期将发布的部分新特性包括:
- 上下文并行(Context Parallel)
- FP8低精度训练
- FP8 Grouped GEMM
- Token-Drop MoE
通过这些特性,Megatron-Core MoE为用户提供了一个强大的MoE训练框架,以在大规模集群上高效地训练和探索大型MoE模型。随着更多功能的推出,我们期待Megatron-Core MoE将在未来的LLM研究和应用中发挥更大的作用。
MoE平台工具
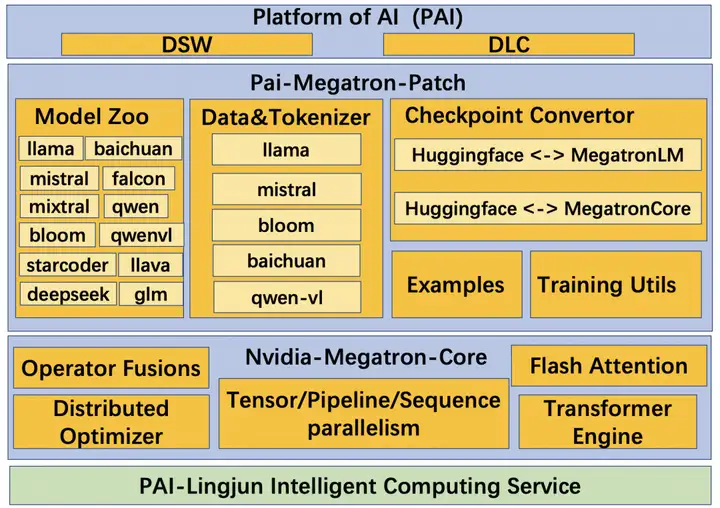
在阿里云PAI灵骏分布式集群上运行的基于Megatron的MoE训练工具由三部分组成(如下图所示)。从上到下依次是PAI平台,PAI-Megatron-Patch 以及NVIDIA Megatron-Core。PAI平台的DSW产品是为AI开发者量身定制的云端机器学习交互式开发IDE,随时随地开启Notebook快速读取数据、开发算法、训练及部署模型。DLC产品则为您提供灵活、稳定、易用和极致性能的多机多卡深度学习训练环境。Pai-Megatron-Patch是各类开源大模型和Megatron训练加速引擎之间的“桥梁”,为用户提供用Megatron训练开源大模型的易用性以及LLM算法场景定制化的灵活性。NVIDIA开发的Megatron以其良好的业界口碑赢得了众多大模型用户的青睐,其算子拆分和流水并行等模型并行技术已经成为行业标准。基于DeepSpeed Zero-1改进的Distributed Optimizer在大规模分布式训练过程中的降显存方面发挥巨大作用。集成最新的算子融合,Transformer Engine以及Flash Attention等训练加速技术更是将大模型的吞吐性能&显卡利用率提升到了极致[3].。
https://github.com/alibaba/Pai-Megatron-Patch
https://github.com/NVIDIA/Megatron-LM
以代码生成这个LLM应用场景为例,研发团队首先在DSW中开发&调试用于该场景的定制化数据处理流程,使用定制化的分词器对原始代码数据进行ID化,同时调试模型库中对应的代码生成模型比如deepseek。接着在DSW中跑通适用于多机多卡训练的HuggingFace到Megatron的权重转换流程并生成Megatron可加载的权重。然后在DLC中配置Patch提供的训练启动脚本,将训练所需的超参数比如学习率以及训练加速开关比如Flash Attention等通过脚本传入Megatron训练引擎。
03
MoE 训练效果展示
我们以最近社区热门的Mixtral-8x7B稀疏MoE大模型为例,从HuggingFace到 Megatron的零样本loss对齐,训练loss收敛曲线,代码生成下游任务评测,训练吞吐性能这四个方面向用户展示训练工具的预期效果,以此来验证工具的可靠性和稳定性。为方便用户测试,我们提供了已经处理好的idxmap格式的Wudao数据集,转换前的HuggingFace模型以及转换后的Megatron-Core格式的模型供下载使用,具体文件大小和下载链接如下所示。


测试镜像地址请采用:
HF 到 Megatron 模型权重转换
由于从头预训练大模型所消耗的算力成本较高,因此用户普遍采用加载 Huggingface 提供已经训练好的模型权重继续预训练或者微调。这就需要先把 HuggingFace的Transformer结构的权重转换到Megatron的Transformer可识别并加载的格式。下图显示的两边的算子之间的对照关系。

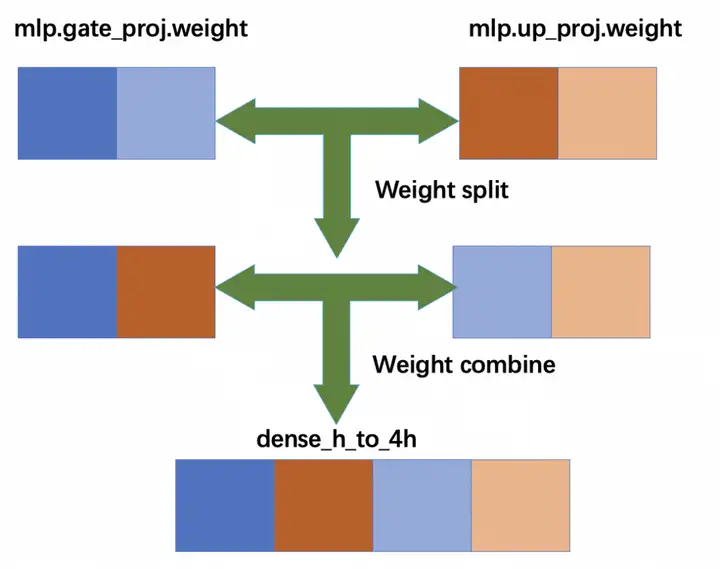
这里需要注意的是当TP>1的时候,对权重矩阵的切分与合并操作应符合Megatron的建模方式。以mlp层的gate_proj和up_proj为例,按TP=2切分后两个算子的左半部分先组合到一起,然后右半部分再组合到一起,然后拼接形成Megatron可识别的dense_h_to_4h操作,如下图所示。这种拆分&合并的顺序一旦出现错误,会导致两边的前向推理无法对齐。
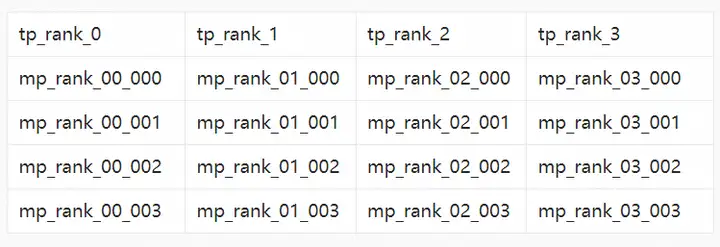
另外涉及到experts的分配的时候也需要格外小心。我们对比dense的转换在moe模型的convert脚本中新增了两个参数(expert_model_parallel_size和world_size(总卡数))来对experts的分布进行精细化处理。比如mixtral的experts的总数是8,那么在16张卡有三种转换情况, tp4ep4, tp8ep2, tp2ep8,按照每种情况来分配moe层的权重。以tp4ep4为例,权重转换后的文件夹命名如下表所示:
在每个文件里存储两个experts的FFN权重,每个tp_rank有8个experts来做路由,如下图所示:
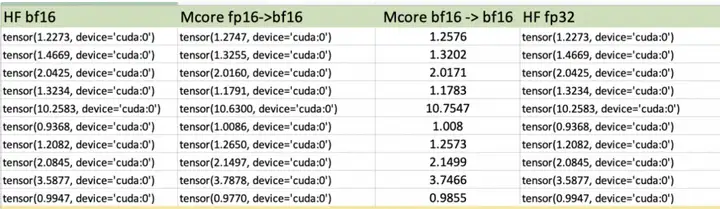
最后我们通过zeroshot loss来衡量转换后的模型是否正确,从下表中可以看到,转换前后的误差基本可以控制在非常小的范围内。下表中箭头精度转换(fp16->bf16)的含义是checkpoint格式是fp16, 运行的时候加载成bf16。
基于 MoE 模型继续预训练 & 微调收敛
我们探索了三个使用场景的收敛情况分别是:从头预训练,加载Mixtral-8x7B-v0.1继续预训练以及加载Mixtral-8x7B-Instruct-v0.1微调。具体操作方法可参考我们提供的Mixtral-8x7B稀疏大模型最佳实践,里面详细介绍了如何启动训练的细节。在从头预训练的实验中,我们采用的训练配置是:A800机型80G显存,两机16卡,global_size=256,lr=1e-4, seq_len=2048, TP=4。训练24个小时到2.4k个step后的loss可以到收敛到1.9的曲线如下所示:
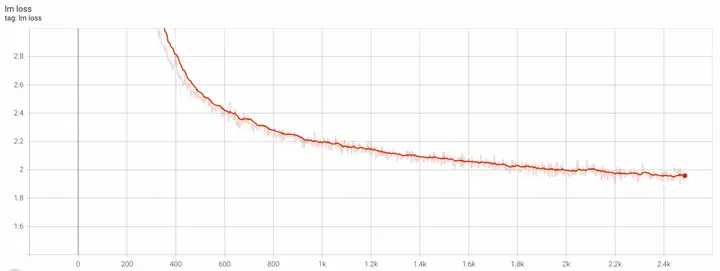
*仅做技术参考和探讨
在加载Mixtral-8x7B-v0.1继续预训练的实验中,我们采用的训练配置是:A800机型80G显存,两机16卡,global_size=256,lr=5e-5, seq_len=2048, TP=4。训练18个小时到2k个step后的loss收敛曲线如下所示:
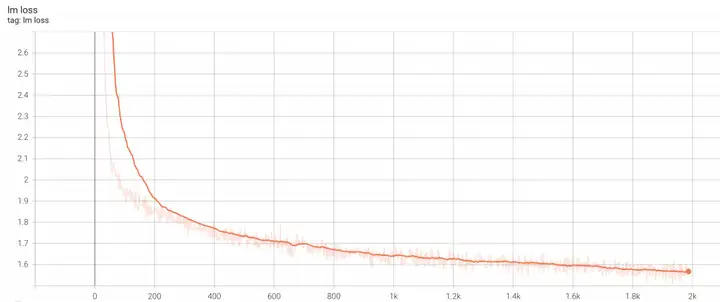
*仅做技术参考和探讨
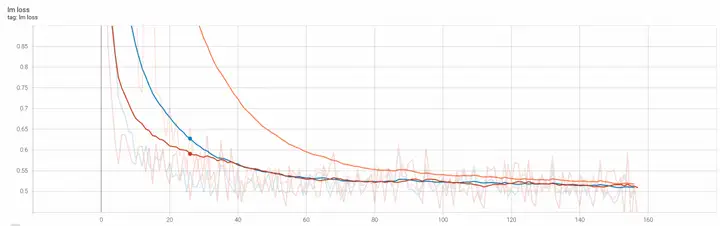
在加载Mixtral-8x7B-Instruct-v0.1微调的实验中,我们在代码生成这个下游任务中设计了三种微调场景分别是:base模型纯自回归训练(橙色曲线,计算全部loss),instruct模型纯自回归训练(蓝色曲线,计算全部loss) 和instruct模型纯自回归训练(红色曲线,计算answer loss)。从三种情况的收敛loss曲线对比可以看出基本都收敛到0.5上下。其中采用base模型来微调的loss下载不如其他两个,这是符合预期的。
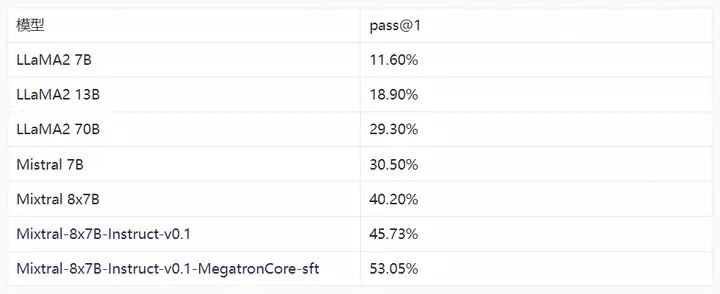
代码生成任务评测
代码生成是指通过自然语言描述生成相应的可执行代码,从而提升开发人员的工作效率。随着LLM模型的不断发展,在代码生成任务上也取得了突破性的进展,如github copilot能够提升55%的开发效率。我们针对代码生成这个下游领域任务,基于Evol-Instruct-Code-80K数据对Mixtral-8x7B-Instruct-v0.1模型进行微调,并测试了在微调前后模型Human-eval上的通过率,和LLaMA2等开源通用模型对比可以看到微调后的模型在代码生成的能力上有明显的优势,如下表所示。
https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1
我们在A800机型80G显存,两机16卡下采用的微调参数如下,具体操作方法可参考我们提供的Mixtral-8x7B稀疏大模型最佳实践。
micro batch size: 1 global batch size: 128 lr: 1e-5 min_lr: 1e-6 seqlen:2048 padlen:2048 tp:4 pp:1 ep:4train_iter:2500
*仅做技术参考和探讨
在评测时,我们使用如下的prompt来生成代码:
f"[INST] Create a Python script for this problem:{question} [/INST]"训练吞吐性能
笔者注:Megatron-Core MoE在短期内还会加入对于通信、计算以及Token dispatch的多项性能优化,当前的测试数据不代表最终的性能数据。
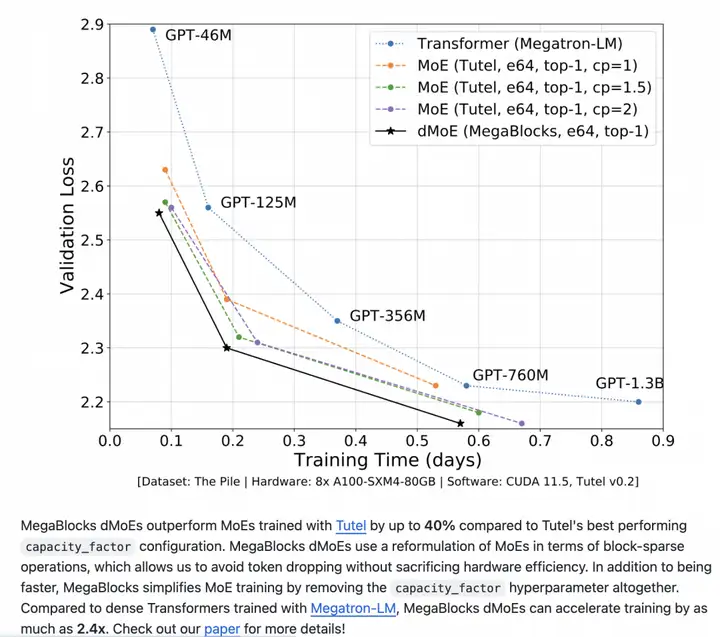
在吞吐速度评测环节,阿里PAI团队调研了Megablocks中的dmoe实现,一方面是因为Mixtral-8x7b论文中说采用的是Megablocks的框架训练的MoE模型,另一方面我们也想探索下在相同Megatron平台底座上,哪个MoE实现方式对训练吞吐加速效果更好。Megablocks论文中提供了同Dense模型的收敛速度的比较,如下图所示的具有2.4x的收敛加速能力,我们期望基于Megatron-Core的实现方案也具有同样甚至更好的加速效果。
https://github.com/stanford-futuredata/Megablocks
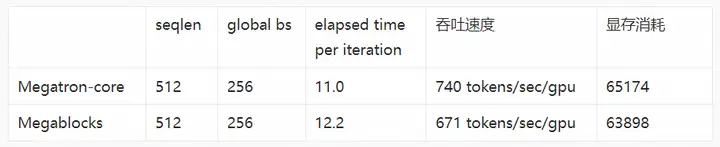
吞吐性能对比实验采用的是阿里云PAI灵骏平台上A800机型80G显存,两机16卡运行环境。我们发现采用Mixtral-8x7B模型配置时,Megablocks的seqlen如果等于1024/2048会出现OOM。因此我们将Megablocks和Megatron-Core的seqlen都设置为512。同时我们打开 --moe-grouped-gemm 开启GroupedGEMM提升多 Experts 时的 GPU 利用率,从下表的吞吐数据可以看出,当前Megatron-Core的吞吐速度比 Megablock 快 10%左右。此外,由于我们得知Megatron-Core当前正在推进MoE的性能优化,因此当前的数据仅供参考。
04
总结
在基于Megatron-Core的稀疏大模型训练工具:阿里云MoE大模型最佳实践开发过程中,我们围绕稀疏大模型训练测试了以下核心技术的性能:
- MoE基础技术平台:基于Megatron-Core MoE的多重训练加速技术的可靠性。
- MoE落地Pipeline:HF到Megatron的模型权重转换在继续预训练&微调以及代码生成下游任务中的效果。
后续在Pai-Megatron-Patch中还会陆续放出更多高质量的大模型最佳实践,敬请期待。
参考文献
[1]. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
[2]. Megablocks: Efficient Sparse Training with Mixture-of-Experts
[3]. Reducing Activation Recomputation in Large Transformer Models







