docker入门不完全指南,这玩艺儿不用则废!
简介
简单地说,docker是一个开放平台,你可以基于它开发、迁移代码以及运行应用。
docker提供了在独立的环境中打包(package)和运行应用的能力,而这种松散(loosely)独立的环境我们一般把它叫做容器(container)。
有了容器,我们可以将我们项目所需要的环境全部一起打包,然后在另一个带有docker的环境比如云服务器上直接安装镜像运行容器,而这个过程我们不需要再去做额外的比如环境搭建之类的。
我们的容器中已经自带了环境了。而且我们可以同时运行多个不同环境的容器,也不用担心它们之间会有环境污染,因为容器之间是相互独立的。
另外docker和CI/CD(continuous integration and continuous delivery)工作流也很搭。
docker的架构
docker使用的是client-server的架构, 客户端也就是提供给用户api的工具(docker compose[3] 也是一个客户端,用于管理多个容器),它会和docker daemon相当于中间层沟通(后面就叫守卫或者dockerd了),它侧重于构建、运行以及分发容器,中间层可以是同个系统的,也可以是远程的。
客户端和守卫之间是通过基于UNIX socket或者网络接口的REST API来联系的。
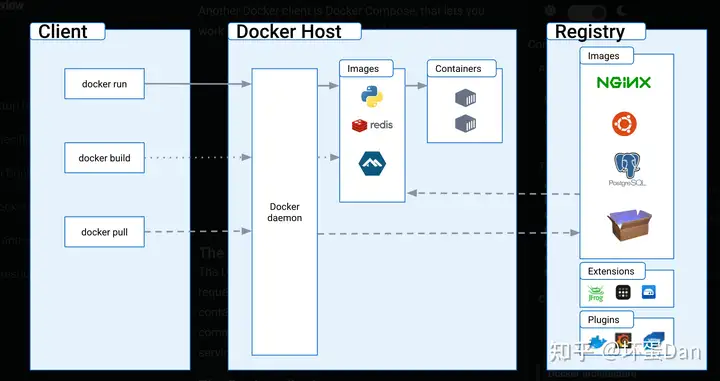
docker daemon
docker守卫(dockerd)会监听请求以及管理docker对象,比如镜像(images)、容器(containers) 、网络以及卷积(volumes)。它也能够和其它守卫建立联系来管理docker服务。
docker client
客户端(docker)是用户主要用来和docker交互的方式,我们输入指令,它会发送给dockerd,然后dockerd会执行它。客户端可以和多个dockerd建立联系。
Docker Desktop
一个可视化应用,支持win/mac/linux三个操作系统,我们可以可视化的创建、构建容器应用和微服务(microservices)。它包含了以下这些内容:Docker daemon (dockerd), the Docker client (docker), Docker Compose, Docker Content Trust, Kubernetes, and Credential Helper。
docker registries
docker有一个注册表用来存储镜像。Docker Hub是一个公共的注册表,任何人都可以从上面下载镜像。而客户端默认也是从这里面下载镜像。当然,你也可以搞一个私有注册表用来放你自己的镜像。
docker objects
前面提到过的镜像、容器、网络、卷积等都是docker对象。
镜像
镜像是一个只读的模板,它提供了创建容器的api。一般情况下,一个镜像是在另一个镜像的基础上自定义的。
比如我们创建的镜像可能是在ubuntu的基础上构建的,不过在这个基础上,我们加了自定义的内容,比如Apache的web服务器以及我们的应用程序,当然还有相关的配置信息。
后面我们会学习到通过Dockerfile批量执行docker指令,然后会在镜像之上创建一个layer,当我们重新构建镜像的时候只会去构建这个layer。
容器
容器是可运行的镜像实例,你可以创建、开始、停止、移除容器。另外我们还可以通过网络来获取容器里的数据,甚至是基于当前容器里的数据再创建一个镜像。
默认情况下,容器是独立的,各容器之间不会有联系。我们可以通过暴露出来的网络端口/数据或者其他容器/主机的底层子系统来操作容器。
容器的定义取决于镜像以及你创建/开启容器时设置的配置项。当容器被移除,任何改变state的数据都将不会被存储。
我们可以用docker run指令创建一个基于某个镜像的容器。比如我们基于ubuntu镜像来创建一个容器
docker run -i -t ubuntu /bin/bash这里假设我们用的是默认的配置项。当运行完这条指令之后,一个基于ubuntu镜像的容器就创建好了(你可以通过docker ps -a来查看容器是否创建)。
这一条指令执行过程中涉及到了如下几个几步:
- 如果你本地没有
ubuntu镜像,那么Docker就会自动帮你从docker registries上面pull下来,相当于你手动docker pull ubuntu。 docker创建一个新的容器,相当于你手动docker container create。docker分配一个读写文件系统(read-write filesystem)给这个新容器,作为它最终的layer。这一步允许了我们的容器创建或者修改本地文件系统的文件和文件夹。docker给容器创建了一个网络接口,这样就能和默认的网络连接上。这里面包含了给容器分配IP地址。默认情况下,容器可以通过主机的网络连接来连接额外的网络。docker开启容器和调用/bin/bash执行容器。我们这里用到了-i和-t两个标志位,所以容器是可通过终端交互的,你可以通过输入关键字来和容器交互,交互的log会被输出在终端。- 我们可以通过输入
exit(一般ctrl + c也行)来终止交互,这样容器就停止了(注意没有移除)。
底层技术
docker是使用go语言编写的并且使用linux内核(kernel)的一些特性来提供功能。docker使用了一种叫namespaces的技术来提供独立的工作空间,即容器。当运行一个容器的时候,docker会给这个容器创建一系列命名空间。而这些命名空间提供了一个独立的layer。容器的每一部分都运行在一个单独的命名空间并且它的访问受限于这个命名空间。
安装
咱本机可以选择安装可视化工具docker desktop。
我这本机是window,所以接下来操作都基于window下的docker desktop。
由于docker底层使用到了linux内核的部分特性,所以我们并不能直接在window上安装docker。
window上安装linux
另外可以搭配:Windows 11 安装 WSL2 - 知乎 (zhihu.com)
这一点如果你在window上安装过redis应该就知道如何处理了。win10在某个版本之后就支持了将linux系统作为子系统,也就是WSL。
系统版本要求

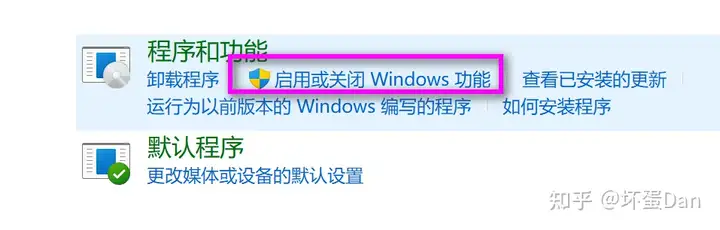
满足先决条件之后打开控制面板的程序的启用或关闭Windows功能
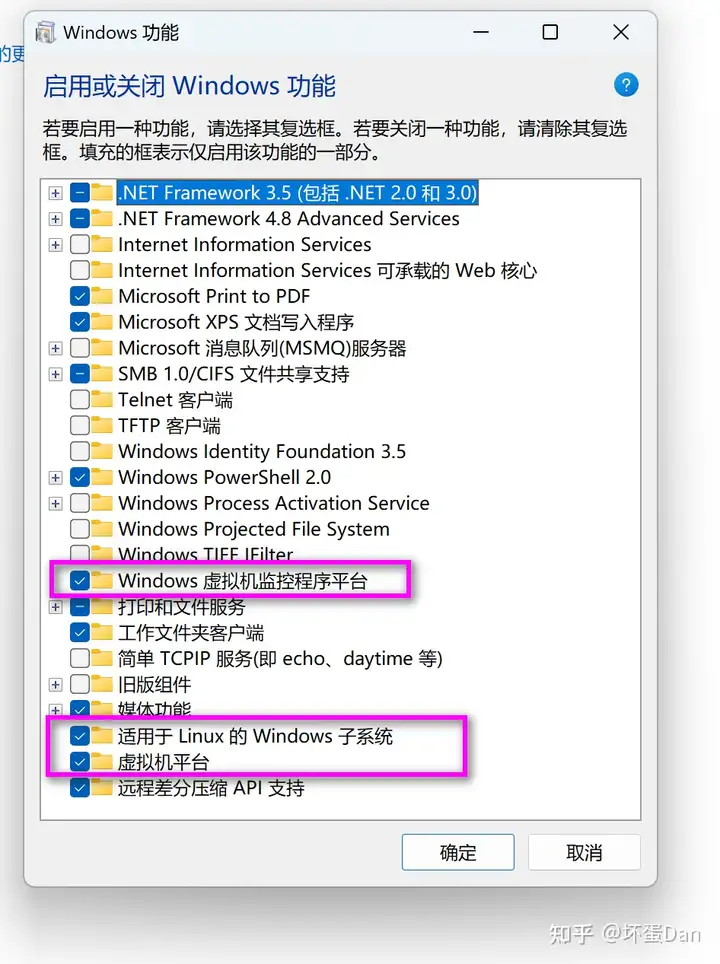
勾上这几个项,我的电脑是win11的,没有Hyper-V,也不影响。
注意这个虚拟机平台必须勾上,不然可能会遇到无法运行ubuntu应用的问题。
接着打开mcrosoft store,搜索ubuntu,选择评分最高那个
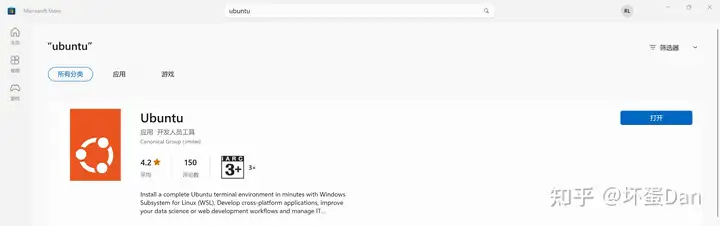
当然你也可以按传统的方式下载ubuntu
wsl --install -d Ubuntu 安装完之后还不能直接打开,由于当前内核的版本并不是最新的,我们还需要升级下版本
通过管理员方式打开powershell,然后输入
bcdedit /set hypervisorlaunchtype auto
wsl --update 稳妥点重启下电脑
然后打开这个ubuntu应用,最开始会让你设置用户名和密码,root并不能直接使用。
这样就表示在window上安装linux成功了。
然后你也可以用hostnamectl看下当前版本。
docker desktop
回到我们最开始的点,我们是想安装docker desktop。
直接到这点击下载应用:Install Docker Desktop on Windows | Docker Documentation
然后安装即可。
docker engine(Ubuntu)
当然,你也可以在之前安装的ubuntu应用打开后通过命令行的方式去安装docker:Install Docker Engine on Ubuntu | Docker Documentation
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin然后测试下是否正常安装
sudo docker run hello-world如果你之前安装过了,你可能需要在安装之前先移除旧版本
for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg; done另外移除docker并不会移除原来的容器等,所以如果你不想要之前的数据,你可以执行以下操作
sudo rm -rf /var/lib/docker
sudo rm -rf /var/lib/containerd 其中/var/lib/docker存放的是镜像、容器、卷积和网络等。具体可见:Install Docker Engine on Ubuntu | Docker Documentation
get started
接下来我们将通过以下的几步来了解和学习docker的用法:
- 构建镜像和运行镜像的容器
- 使用
docker hub分享你的镜像 - 使用具有数据库的多个容器部署 Docker 应用程序
- 使用
Docker Compose运行程序
不过在开始之前,我们需要再加深对容器和镜像概念的理解。
什么是容器?
容器实际上是一个在你主机上独立、有别于其它进程的沙盒(sandboxed)进程。
如何实现的独立,前面说过是基于linux内核的namespace技术,具体可见:Demystifying Containers - Part I: Kernel Space | by Sascha Grunert | Medium
总之,容器具有以下特性:
- 是镜像的可运行实例,你可以使用
create、start、stop以及delete这几个api来操作容器 - 可以运行在宿主机、虚拟机和云端部署
- 便携式的(
portable),可以运行在所有OS中 - 独立于其它容器,运行它自己软件、二进制(
binaries)以及配置
什么是镜像?
前面我们知道了容器是运行在镜像之上的文件系统,而容器又可以跑你的应用。那么作为容器的基础:镜像自然就需要包含所有容器需要的东西,比如依赖、配置等。
我们后面会深入了解到镜像。
(我怀疑简介和这一章不是同一个老哥写的)
打包(containerize)一个应用镜像
接下来我们将搞一个web前端应用,基础环境自然就是nodeJS的。
什么?你没用过nodejs?请出门左拐:Node.js
噢,你先别拐,咱这只是将它作为环境依赖安装下,并不会用到里面的api等。
先在本机创建一个docker-study的文件夹, 然后拉个官方给的demo
mkdir docker-study
cd docker-study
git clone https://github.com/docker/getting-started.git这个git分支貌似需要开魔法才能拉下来。。。
这应该是一个workspaces。我们的目标在app文件夹里。
项目里的代码我们不用去探究了解,我们的目的是知道如何打包和运行。
我们在app根目录创建一个Dockerfile文件。
t# syntax=docker/dockerfile:1
FROM node:18-alpine
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "src/index.js"]
EXPOSE 3000这里面几行是在干啥我们暂时不分析,现在我们可以开始构建镜像了。
docker build -t getting-started .docker build:构建容器镜像的指令-t:tag,也就是你镜像的名字.:这最后一个点表示需要在当前目录下查找Dockerfile

这时你的docker desktop里应该就会看到我们刚打包的镜像
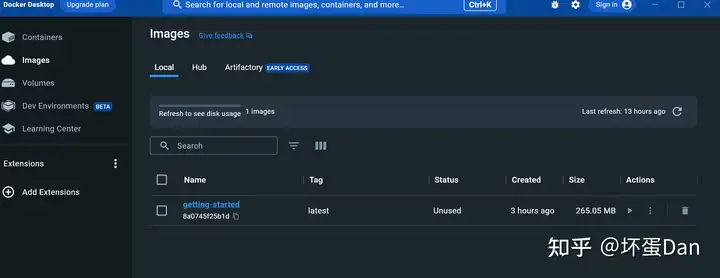
打包的过程中可能下载了一堆的layer,这是因为我们前面在Dockerfile里FROM node:18-alpine,我们需要nodejs环境,如果你电脑没有,就会先下载对应的镜像。
然后我们回过头来分析下Dockerfile里的内容:
FROM[13]node:18-alpine:我们希望基于node:18-alpine这个镜像上开始构建镜像。
FROM [--platform=<platform>] <image> [AS <name>]
// or
FROM [--platform=<platform>] <image>[:<tag>] [AS <name>]
// or
FROM [--platform=<platform>] <image>[@<digest>] [AS <name>]WORKDIR[14]/app:工作目录,其余指令比如RUN/CMD等的执行目录,可以指定多个,下面这样的相当于/a/b/c
WORKDIR /a
WORKDIR b
WORKDIR c
RUN pwdCOPY[15]. .:复制新文件(夹)到目标目录,目标目录作为容器的文件系统目录
COPY [--chown=<user>:<group>] [--chmod=<perms>] <src>... <dest>
COPY [--chown=<user>:<group>] [--chmod=<perms>] ["<src>",... "<dest>"]RUN[16]yarn install --production: 执行yarn install指令,--production是参数。这个api执行时会在最顶层创建一个layer,然后把执行的结果提交出去给下一步指令。
RUN <command> // (shell form, the command is run in a shell, which by default is /bin/sh -c on Linux or cmd /S /C on Windows)
RUN ["executable", "param1", "param2"] // (exec form)CMD ["node", "src/index.js"]:调用node运行src/index.js文件。 一个Dockerfile只能有一个CMD,如果你写了多个则按最后一个为准。 你可能觉得这个CMD和RUN作用有些类似,实际上两者做的事情并不一样,CMD是作为执行容器的默认值,而RUN则是容器执行前的一系列操作。 你也可以用ENTRYPOINT进行覆盖,格式均为JSON数组。
CMD ["executable","param1","param2"] // (exec form, this is the preferred form)
CMD ["param1","param2"] // (as default parameters to ENTRYPOINT)
CMD command param1 param2 // (shell form)EXPOSE[17]3000: 容器监听的端口,默认是TCP的,也可以设置成UDP。 实际上这里并没有真正的暴露端口,而是相当于文档类型一样。如果有着需要,docker run的时候你可以带上-p参数。
EXPOSE <port> [<port>/<protocol>...]
//example
EXPOSE 80/tcp
EXPOSE 80/udp比如:
docker run -p 80:80/tcp -p 80:80/udp ...这个例子如果带上-p,会同时创建两个端口,一个tcp和一个udp的。
运行容器[18]
现在我们已经有了镜像,要创建并运行容器只需要简单的一个指令。
docker run -dp 127.0.0.1:3000:3000 getting-started-dp:是-d和-p的简写-p:前面说过了,是--publish的缩写-d:是--detached的缩写,这样你的容器就可以在后台运行127.0.0.1:3000:3000:格式为HOST: CONTAINER。127.0.0.1:3000是Host,表示主机的地址加端口,这个端口你可以用来暴露到公网等,而后面的3000则表示容器监听的端口,这俩端口不必一致,实际上是做了一层映射。getting-started:我们的镜像名字

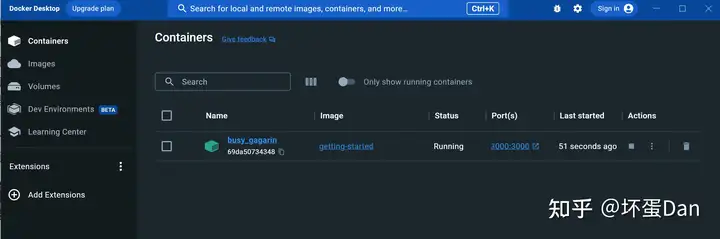
然后我们直接访问localhost:3000
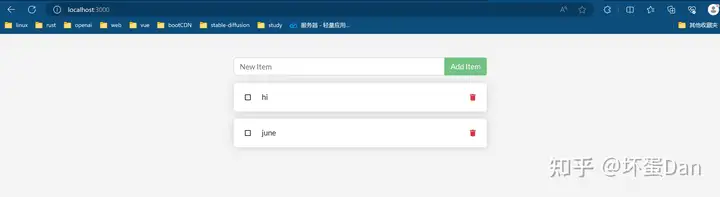
这样我们的容器就在后台跑起来了
下面我们来更新下我们的应用
更新应用[19]
首先我们来修改下项目的代码
找到src/static/js/app.js文件
- <p className="text-center">No items yet! Add one above!</p>
+ <p className="text-center">You have no todo items yet! Add one above!</p> 然后回到app文件夹里,我们需要重新构建一次镜像。
docker build -t getting-started . 构建完之后先暂时不要执行运行容器的指令,由于镜像已经被占用了,所以这个时候你运行容器可能会失败,因为当前镜像已经有一个运行中的容器了。
我们需要先删除对应的容器
docker-desktop中直接找到container那一栏删掉对应的容器即可,命令行的如下
docker stop <container-id> // <container-name>
docker rm <container-id> // <container-name> 
移除之前需要先停止容器运行。
然后再重新执行容器运行的指令
docker run -dp 127.0.0.1:3000:3000 getting-started
这样就完成了。
分享应用[20]
我们可以把我们的app上传到docker hub上,这样别人或者自己的另一台机器上就可以下载你这个app了。
在我们上传自己的app之前,我们需要先注册一个docker账号:https://www.docker.com/pricing?utm_source=docker&utm_medium=webreferral&utm_campaign=docs_driven_upgrade&_gl=1*115ovx7*_ga*NjcwMzA0MTY3LjE2ODAxODI2MzY.*_ga_XJWPQMJYHQ*MTY4NzU3MDU3Mi4xNi4xLjE2ODc1NzI5NjkuMjcuMC4w
然后来这创建一个仓库:

注意要选择public,这样别人才能pull的到你的镜像。
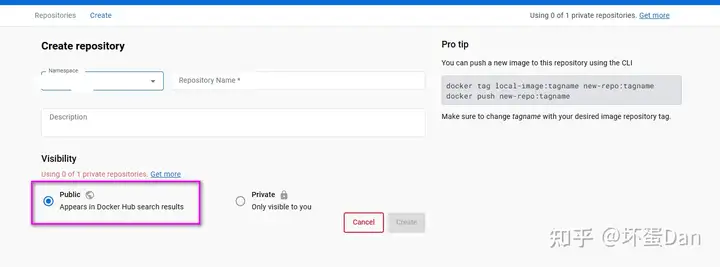
当然,我们一般都是自己用的(要钱)。。
name:是你发布的镜像的名字
设置完了点击create。
创建好了屏幕右边可以看到一个指令提示
docker push [yourname]/[respository]:[tag]tag:这个指的是版本,默认是latestrespository:这个要和你的镜像名字对应上yourname:这个是你的用户名,记得先登录docker desktop,如果你是用命令行的,你需要使用一下指令进行登录
docker login -u YOUR-USER-NAME我们回到我们的项目中执行如下指令
docker push [yourname]/[respository]然后你会发现报错了

没有对应的镜像
这个时候我们就需要用到tag[21]修改已有镜像的名字
docker tag getting-started YOUR-USER-NAME/getting-started 
然后我们再重新执行push指令
但这里我们又遇到另一个问题
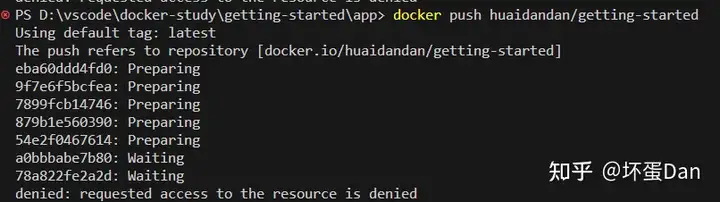
这个问题是因为我们先用docker desktop登陆了,所以我们现在需要先logout,然后重新登录
docker logout
docker login -u "mazeyqian" -p "Password" docker.io
docker push [yourname]/getting-started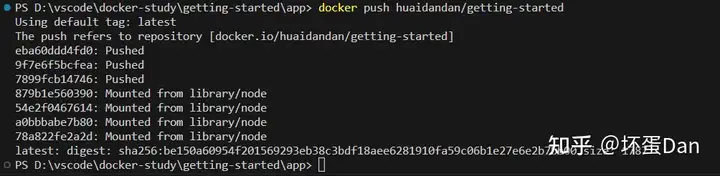
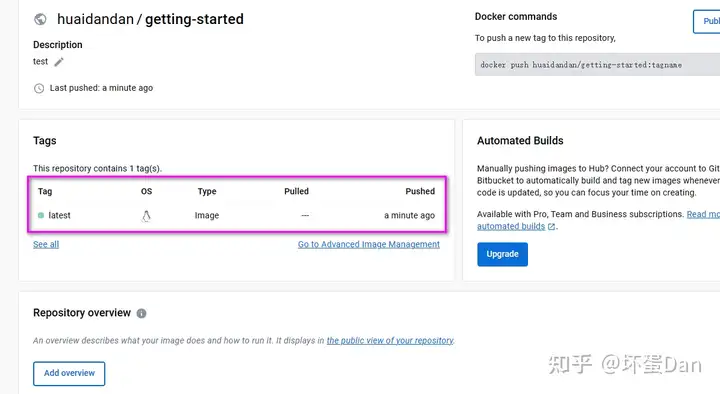
这样就发布成功了,我们在本机也可以用docker search的方式查看
docker search [yourname]/getting-started 
然后我们可以将它拉下来运行,如果你有另一台机器,你可以在那台机器上试下,或者来到官方提供的线上平台试下:Play with Docker
流程和之前一样的,我这里就不演示了
持久化数据库[22]
目前我们的数据是非持久性的,每次重新创建容器之后数据就都没了,前面说过容器之间是独立的(即使是基于同一个镜像的容器数据也不共享),所以默认数据是不会出现在容器外的。
我们现在来将数据同步到本机来实现持久化。
项目中使用的数据库是SQLite[23] , 默认数据是存储在/etc/todos/todo.db里面,所以如果我们有个东西把里的数据包裹起来放到本机,那么即使镜像都没了我们的数据也不会丢失。
这个时候就需要用到挂载(mount)卷积(valumes[24])了
docker volume create todo-db
docker run -dp 127.0.0.1:3000:3000 --mount type=volume,src=todo-db,target=/etc/todos getting-started--mount:用于指定要挂载到的对应卷积/etc/todos:卷积挂载的对象,在容器里。
这样数据就可以持久了,我们可以重新创建容器和运行,然后随便搞点数据之后再移除容器,然后再创建一个容器并运行,这个时候你就会看到之前的数据还保留着
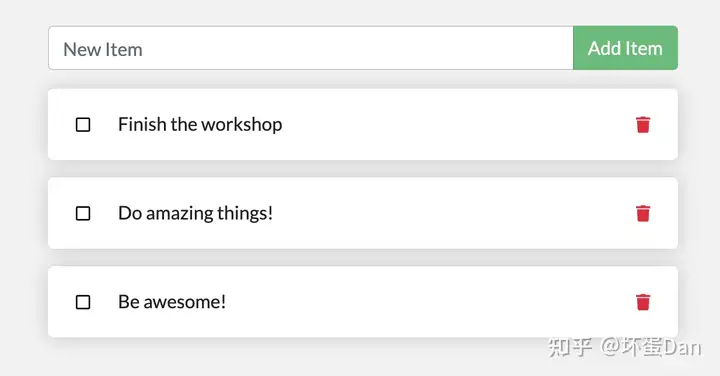
现在我们的数据就被保留在卷积中了。
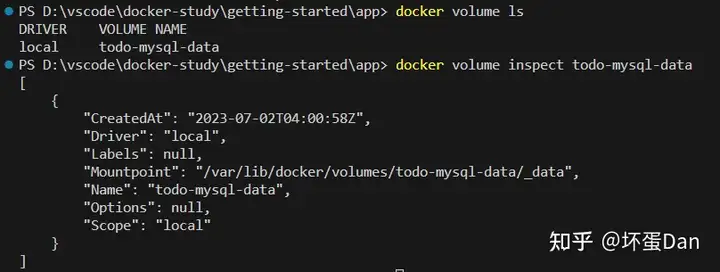
然后我们可以通过docker volume inspect指令去查看卷积存放的位置,确保数据是有持久化的。
docker volume inspect todo-db
[
{
"CreatedAt": "2019-09-26T02:18:36Z",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/todo-db/_data",
"Name": "todo-db",
"Options": {},
"Scope": "local"
}
] (在公司,没有配置环境,所以直接用官方给的例子了。。)
Mountpoint:磁盘存放的位置,也就是我们持久化的数据所在位置。
使用bind的方式挂载[25]
实际上我们还可以自定义存放的位置,通过bind的方式将主机本机的文件夹绑定到容器里,当分享的文件夹内容发生变化的时候会立即同步容器里的数据。
我们先来看下这两种方式的区别
| 具名卷积(named volumes) | 绑定挂载(Bind mounts) | |
|---|---|---|
| 主机位置(Host location) | 由docker选择 | 开发者设备 |
| 挂载例子 (using --mount) | type=volume,src=my-volume,target=/usr/local/data | type=bind,src=/path/to/data,target=/usr/local/data |
| 使用容器内容填充新的卷积 | 是 | 否 |
| 支持卷驱动程序 | 是 | 否 |
回到我们的app文件夹中,我们来试下
docker run -it --mount type=bind,src="$(pwd)",target=/src ubuntu bash // linux/unix
docker run -it --mount "type=bind,src=$pwd,target=/src" ubuntu bash // windows powerShell--mount:通知docker我这里是使用的绑定挂载的方式-it:会创建一个伪的可交互终端,我们这就是一个ubuntu的容器终端src:当前工作文件夹target:容器里你想绑定的文件夹
执行了指令之后我们会直接进入容器的文件系统

然后我们进入src文件夹中,创建一个test.txt文件,这个时候你就会看到这个文件在我们的设备上也是同时生成的。
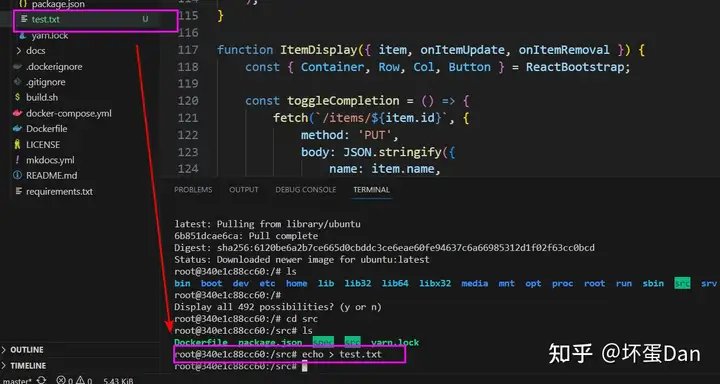
然后我们在设备上直接删除这个test.txt文件再在终端输入ls
这个时候就看不到之前创建的test.txt文件了

这么一看我们的文件夹确实绑定好了容器src文件夹了
终结终端使用Ctrl + D。
这种方式下有些东西比如工具之类的我们并不需要单独去安装,都是会同步的。
然后我们再来将我们的app做一波这个流程,不过在这之前,我们需要先docker ps -a看下是否存在运行中的getting-started容器,如果有,先移除。
// linux/unix
docker run -dp 127.0.0.1:3000:3000 \
-w /app --mount type=bind,src="$(pwd)",target=/app \
node:18-alpine \
sh -c "yarn install && yarn run dev"
// windows
docker run -dp 127.0.0.1:3000:3000 `
-w /app --mount "type=bind,src=$pwd,target=/app" `
node:18-alpine `
sh -c "yarn install && yarn run dev"-dp:前面说过了,就是-d和-p的简写-w:指定工作目录,这里指定的是app文件夹作为执行后续指令的文件夹node:18-alpine:不多说,就是基于node镜像搭建容器sh -c "yarn install && yarn run dev":调用sh来执行安装依赖和运行的指令,alpine没有bash的。nodemon[26]:dev这个指令执行的是nodemon src/index.js。这个nodemon是一个node工具,可以在程序内容发生变化的时候自动重新运行程序。
然后我们可以docker ps -a看下容器是否正常运行

或者直接浏览器或者curl访问localhost:3000看是否正常。
如果没正常运行起来,我们可以通过docker logs -f <container-id>的方式来查看错误信息
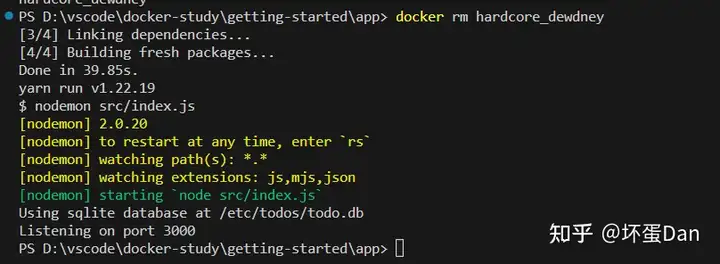
可以看到我这里是正常的log
然后我们随便找个文件getting-started\app\src\static\js\app.js修改内容,注意要在本机修改
然后直接回到之前打开的localhost:3000,刷新下,这个时候按钮的文案就变了。
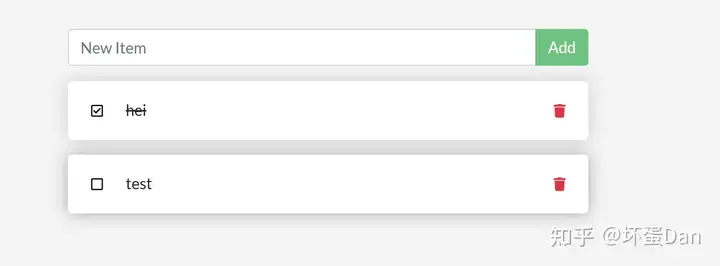
当我们开发完毕之后,我们直接删掉这个容器,打包镜像发布就完事了
docker build -t getting-started .当然,这个nodemon并不能做到热更新的效果,如果真要开发直接用webpack/vite即可。
多容器应用[27]
前面我们的项目里涉及到的东西都是直接放到同一个容器里的,比如数据库数据等,而实际上应该把他们拆开,尽量做到专注于某部分,因为如果不同技术涉及到的环境、环境变量、工具等会使得这容器变得复杂,维护成本高。
现在我们再搞个MySQL的容器来运行我们的数据库。
不过这里还有个问题,那就是网络。由于容器之间相互独立隔离,它们并不知道彼此,所以也不能直接联系。这个时候我们可以使用network,如果这俩都在同一个网络下,那么它们就可以做到相互联系。
docker network create todo-app创建一个叫做todo-app的网络
然后我们创建一个MySQL容器并指向这个网络
// linux/unix
docker run -d \
--network todo-app --network-alias mysql \
-v todo-mysql-data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=secret \
-e MYSQL_DATABASE=todos \
mysql:8.0
// windows
docker run -d `
--network todo-app --network-alias mysql `
-v todo-mysql-data:/var/lib/mysql `
-e MYSQL_ROOT_PASSWORD=secret `
-e MYSQL_DATABASE=todos `
mysql:8.0-v:是--volume的简写

-e:设置环境变量MYSQL_ROOT_PASSWORD:MySQL的密码MYSQL_DATABASE:指定的数据库,环境变量相关的具体可见:MySQL Docker Hub listing.--network-alias: 搞个别名,这样比较好分辨,虽然还是同一个network

这里我们并没有使用docker volume create,而是直接 todo-mysql-data:/var/lib/mysql,这里是通知docker我们想创建一个todo-mysql-data名字的卷积,如果没有这个卷积会自动创建并挂载/var/lib/mysql这个数据。
接下来我们来测试下是否正常创建容器
docker exec -it <mysql-container-id> mysql -u root -pexec:在一个运行中的容器中执行指令,这里的指令是mysql -u root -p

默认用的bash,所以可以不写。
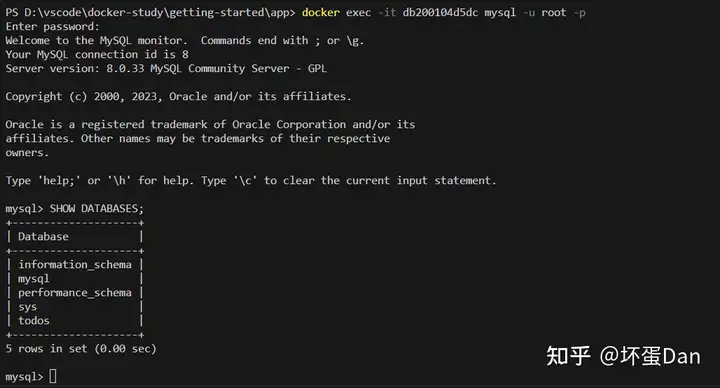
可以看到我们前面设置的,这会儿已经有了todos数据库。
然后exit可以退出
然后我们准备在另一个容器中连接这个数据库,每一个容器都有自己的ip地址,所以在同一个网络里我们可以通过ip去定位容器。
我们先用nicolaka/netshoot来试下,这个镜像里面包含着很多的网络工具
docker run -it --network todo-app nicolaka/netshoot
// 然后在新终端中输入
dig mysql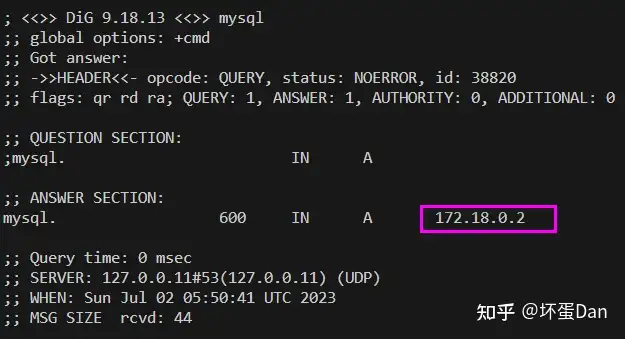
dig命令是一个DNS工具。
这个172.18.0.2就是我们的网络,每个人的都不同。
这个mysql是容器的网络别名,我们前面用--network-alias定义的,到时候docker会解析这个mysql编程正确的ip地址。我们后面连接的时候直接用这个mysql别名即可。
这个app的项目中支持了几个环境变量可以直接接入mysql,所以我们直接配置下即可。
// linux/unix
docker run -dp 127.0.0.1:3000:3000 \
-w /app -v "$(pwd):/app" \
--network todo-app \
-e MYSQL_HOST=mysql \
-e MYSQL_USER=root \
-e MYSQL_PASSWORD=secret \
-e MYSQL_DB=todos \
node:18-alpine \
sh -c "yarn install && yarn run dev"
// windows
docker run -dp 127.0.0.1:3000:3000 `
-w /app -v "$(pwd):/app" `
--network todo-app `
-e MYSQL_HOST=mysql `
-e MYSQL_USER=root `
-e MYSQL_PASSWORD=secret `
-e MYSQL_DB=todos `
node:18-alpine `
sh -c "yarn install && yarn run dev" 别忘了先移除之前app的容器
然后我们打开页面随便加点数据
然后我们进去mysql容器中,看下数据是否正常
docker exec -it <mysql-container-id> mysql -p todos查看下数据
select * from todo_items;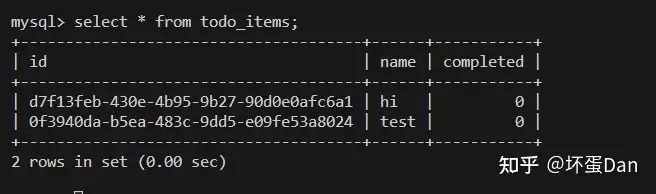
正常
使用Docker Compose[28]
现在我们的项目已经是多容器的了,但是一般一个项目一般不只有两个容器,随着容器的增多后续维护成本会增高。
另外容器太多,要打包成镜像一个一个发布和安装就会非常繁琐。
这个时候就需要有一个管理器用来统管这些容器,比如k8s[29]。
不过这里我们只要用的是Docker Compose
我们先来安装下(安装docker desktop的忽略,自带了):Install the Compose plugin
// ubuntu/debain
sudo apt-get update
sudo apt-get install docker-compose-plugin
// RPM-based distros
sudo yum update
sudo yum install docker-compose-plugin安装完之后,可以检验下安装是否正常
docker compose version 
另外里面还教了如何手动安装docker compose,如果你想要这种方式请自行翻看文档,这里就不说了。
安装完之后我们回到app文件夹中创建一个docker-compose.yml的文件
services:services:最开始需要定义需要管理的服务或者是容器,到时候打包的时候这些定义的服务都将作为其中一部分。
然后我们定义第一部分
services:
app:
image: node:18-alpine
command: sh -c "yarn install && yarn run dev"
ports:
- 127.0.0.1:3000:3000
working_dir: /app
volumes:
- ./:/app
environment:
MYSQL_HOST: mysql
MYSQL_USER: root
MYSQL_PASSWORD: secret
MYSQL_DB: todosapp: 这个是service的名字,后面会作为网络的别名,可以是任意的,不必是app。image:这个service的镜像command:这个服务开启后要执行的指令,非必要,也不需要固定顺序,不过一般都放在image下面ports:服务端口,这个项有两种写法,一种简洁,另一种详细,具体可见:short syntax,long syntax
// short example
ports:
- "3000"
- "3000-3005"
- "8000:8000"
- "9090-9091:8080-8081"
- "49100:22"
- "8000-9000:80"
- "127.0.0.1:8001:8001"
- "127.0.0.1:5000-5010:5000-5010"
- "6060:6060/udp"
// long example
ports:
- target: 80
host_ip: 127.0.0.1
published: "8080"
protocol: tcp
mode: host
- target: 80
host_ip: 127.0.0.1
published: "8000-9000"
protocol: tcp
mode: host ok,然后我们再来配置mysql的。
services:
app:
// ...
mysql:
image: mysql:8.0
volumes:
- todo-mysql-data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: secret
MYSQL_DATABASE: todos
volumes:
todo-mysql-data:volumes:注意这里的volumes是和services同级的。这个的作用是告知docker compose要创建一个todo-mysql-data的卷积,compose并不能识别是否需要自动创建卷积。详见:Volumes top-level element
最终这个docker-compose.yml内容如下:
services:
app:
image: node:18-alpine
command: sh -c "yarn install && yarn run dev"
ports:
- 127.0.0.1:3000:3000
working_dir: /app
volumes:
- ./:/app
environment:
MYSQL_HOST: mysql
MYSQL_USER: root
MYSQL_PASSWORD: secret
MYSQL_DB: todos
mysql:
image: mysql:8.0
volumes:
- todo-mysql-data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: secret
MYSQL_DATABASE: todos
volumes:
todo-mysql-data: 现在我们可以来试着运行下了,不过在这之前,确保mysql和app这俩容器都移除了
然后我们就能运行了
docker compose up -d 
-d:这个和之前介绍的是一样的,都是在后台运行
这个时候我们在docker ps -a可以看到之前移除的容器又出现了

我们再来访问下浏览器
正常访问
或者你也可以看下log
docker compose logs -f <service-name>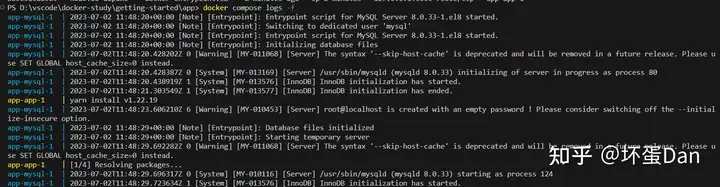
然后我们回到docker desktop中,这个时候你会发现容器只剩下一个app

另外说下移除的步骤
docker compose down这样就移除了,不过需要注意的是默认不会移除卷积,如果你有这个需要,你需要加上参数:--volumes。
docker desktop中点击右侧删除按钮即可,不过通过这种方式移除的是没法子顺便移除卷积的。

镜像构建最佳实践[30]
我们现在已经知道镜像是一个个layer堆叠起来的,但是我们并不清楚这些layer是哪些,这个时候就可以使用
docker image history <image-name>这个指令来查看是哪些
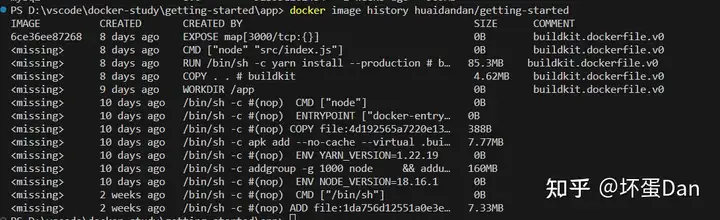
有些内容被遮盖了,如果你想看全,你可以带上--no-trunc这个参数
现在我们可以看到所有的layer了,那么我们就能分析这些layer来优化以达到减少构建时间的效果。
另外提一嘴,当其中一层layer改变之后,它往上的所有层都会重新创建,因为每层layer都可能依赖于它前面那层。
我们先来看个例子的Dockerfile
# syntax=docker/dockerfile:1
FROM node:18-alpine
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "src/index.js"] 这里每一个指令都会创建一层layer。而根据前面知道的知识,如果其中一层变化了,那么后面所有层都要跟着变。这个时候就很浪费时间了,因为后面的所有层我们没有改动,我们没必要每次都去让它们重新构建,比如这个yarn install --production,每次都需要重新安装依赖。
这个时候最简单的方案自然就是缓存。
这里我们只需要调整下yarn install的位置,让它在copy之前执行,那么它就只会安装依赖一次。
# syntax=docker/dockerfile:1
FROM node:18-alpine
WORKDIR /app
COPY package.json yarn.lock ./
RUN yarn install --production
COPY . .
CMD ["node", "src/index.js"] 后面除了package.json之外任何文件的改动都不会再触发这个yarn install。
然后我们再搞个.dockerignore文件用来忽略某些会被复制到的东西,作用和.gitignore一样。
node_modules详情可见:Dockerfile reference
更多node相关的项目可以参考这篇:Dockerizing a Node.js web app | Node.js
最后我们再重新构建(别忘了开魔法)
docker build -t getting-started .构建完之后我们改下src/static/index.html文件内容
然后我们再重新构建
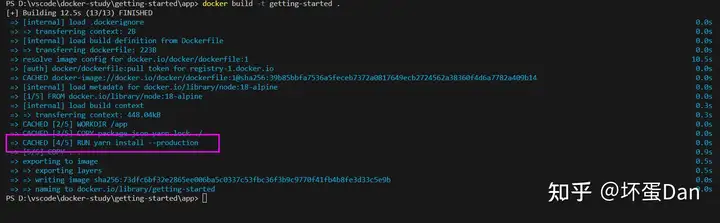
现在构建就少了这一步了,构建耗时也是少了很多
然后我们来简单接触下多阶段构建(multi-stage builds)
多阶段构建的好处:
- 将一些
build-time依赖从runtime依赖分离,减少运行时构建时间 - 减少镜像体积,只包含程序运行需要的。
这里以Maven/Tomcat为例子,比如JDK在编译阶段是必要的,但是对于runtime来说并不需要,所以这个时候我们就需要去掉不必要的
# syntax=docker/dockerfile:1
FROM maven AS build
WORKDIR /app
COPY . .
RUN mvn package
FROM tomcat
COPY --from=build /app/target/file.war /usr/local/tomcat/webapps 这里我们先构建maven,这个构建别名为build,然后第二阶段构建直接从maven里复制需要的内容即可。
这里我不是很懂,如果说错了,麻烦评论区说下,谢谢~
再来个react项目的例子
如果不考虑SSR等,我们甚至不需要node环境,所以直接复制html/js/css到nginx上即可。
# syntax=docker/dockerfile:1
FROM node:18 AS build
WORKDIR /app
COPY package* yarn.lock ./
RUN yarn install
COPY public ./public
COPY src ./src
RUN yarn run build
FROM nginx:alpine
COPY --from=build /app/build /usr/share/nginx/html 那么到这我们的入门就差不多了
总结
这玩意儿要实战才行,不然一学就会,一用就废~
另外docker和云原生也有关系,比如k8s。







