k8s调度流程梳理:为创建的 pod 找到合适的 node
k8s 调度做的事情很简单,就是为创建的 pod 找到合适的 node,找到后直接发送一个 v1.Binding 资源对象给 apiserver 。但整个过程是很复杂的。
k8s 调度模块本来就比较复杂的了,不仅逻辑复杂,还涉及到很多概念。所以这篇文章主要是梳理调度流程,一些重要的概念这里我们只是简单介绍下,知道是干什么的,具体细节会再出文章介绍。
(本文源码引用的版本是 v1.23.14)
重要概念
先简单介绍一下重要的概念
调度框架
即 大名鼎鼎的 scheduler framework,是一个 interface。即类似于 cni, csi 一样定义接口,我们可以自己实现方便扩展。 仔细去看
type Framework interface源码,其实就是一些列的 Plugins 调用方法。
源码里也只有一个实现实例frameworkImpl
cache 本地化
即把 node 信息和 pod 信息缓存到本地了!为啥要这样,可以先不用知道。
记住node 信息 和 pod 信息 可以在本地获取,而且不用担心和 apiserver 数据不一致的问题!
Assume
乐观假设,也可以理解为模拟行为。 这是一种提高性能的设计,即调度需要的 node 和 pod 信息直接从 cache 中取,而没有从 apiserver 获取。
整个调度并没有真正发生,是通过本地 cache 的信息模拟地调度(pod.spec.NodeName = nodeName 就算调度成功)。
这么做的的目的是为了减少跟 apiserver 的交互(毕竟是一次消耗性能的I/O)。通过 Assume 这钟设计也就明白了 cache 本地化的必要性
调度队列
即
type SchedulingQueue interface也是一个 抽象 interface ,实例也只有一个PriorityQueue。 其中的activeQ、podBackoffQ、unschedulableQ跟调度有关 。
新建的pod,以及待调度的 pod 都在 activeQ 中。
podBackoffQ 即延迟调度队列,队列会有一个默认的延时时间。如果调度性能下降调度慢的话, pod 就会进入这里。这里再补充一个 backoff 的机制
backoff机制是并发编程中常见的一种机制,即如果任务反复执行依旧失败,则会按次增长等待调度时间,降低重试效率,从而避免反复失败浪费调度资源调度失败的 pod 都会进入 unschedulableQ 队列中。
这里我们知道在调度的时候,pod 都是从 activeQ 队列里面取的。
至于 podBackoffQ 和 unschedulableQ 中的 pod 如何到 activeQ 中这算是细节,后面会出调度细节的详细文章,这里可以不用关心,也不会影响对调度流程的理解。
Extension points
这些 points 才是扩展 调度框架的关键。看下图
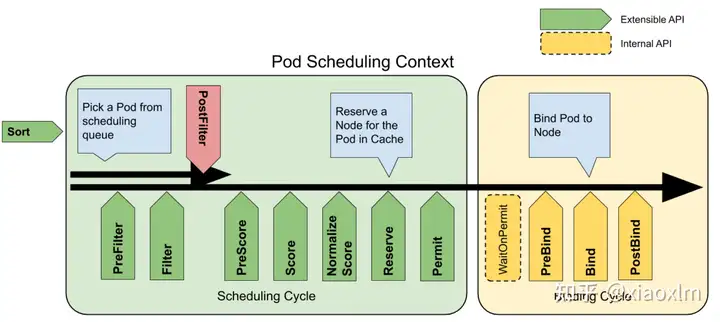
那条贯穿绿色和黄色模块的箭头,就是一个 pod 成功调度”要走的路“。
绿色模块叫调度周期。 主要有2个阶段,一个阶段叫 filter 用于过滤出符合要求的可调度 node 集合;另一个叫 score,选出最高分的 node 作为最终调度到的地方。
(可能你见到叫 Predicates 和 Prioritize 两个阶段。 Predicates 是 filter 以前的叫法,Prioritize 就是 打分 score )
黄色模块叫绑定周期。
里面绿色、红色、黄色的箭标就叫 Extension points, pod 调度路上一个一个的"检查点"!有些地方把Extension points就直接叫 plugins,也没问题因为每一个 "检查点" 都是由一个或多个 plugins 组合而成,这些 plugins 你可以想象成不同的"检查官"。 这点会在文章"调度流程"这一节中了解到。
KubeSchedulerProfile
KubeSchedulerProfile 是比较重要的概念,主要就是用于扩展自定义的调度框架,以及配合 KubeSchedulerConfiguration 配置涉及到的 plugins 。
但这里不了解这个东西不影响明白整个调度流程。
还是那句话,这篇文章重点是梳理调度流程。
调度流程
整个调度的源码入库是在 :
// cmd/kube-scheduler/app/server.go
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
...
...
cc, sched, err := Setup(ctx, opts, registryOptions...) // 初始化 scheduler
if err != nil {
return err
}
return Run(ctx, cc, sched) // 开始调度
}
开始调度前思考一个问题,如何拿到新创建的pod?
如果看过之前的 深入k8s -- Controller源码分析 ,肯定会有感觉,k8s 所有资源的监听都是通过 informer。
这里也是一样的。在 scheduler.New() 中的 addAllEventHandlers() ,就可以到相关代码。里面不仅有 pod,还有 node 等其他事件。
好了,调度流程正文开始了!
sched.SchedulingQueue.Run() 将其他队列的pod 加到 activeQ 中
真正执行调度逻辑的地方 sched.scheduleOne, 咱们就直接看关键源码吧,一些不太重要的就省略了,比如 metric 相关的:
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// 从 activeQ 中 pop 出 一个 pod
// 到底是pop 最新 pod,还是最老pod呢?
podInfo := sched.NextPod()
...
// 根据 pod.Spec.SchedulerName 拿到对应的调度框架实例(这里是 default-scheduler)
fwk, err := sched.frameworkForPod(pod)
...
...
// filter 和 score 后 返回最优节点
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, sched.Extenders, fwk, state, pod)
if err != nil {
var nominatingInfo *framework.NominatingInfo
reason := v1.PodReasonUnschedulable
if fitError, ok := err.(*framework.FitError); ok { // 调度失败
if !fwk.HasPostFilterPlugins() { // 默认调度框架是会有 postFilterPlugins的
klog.V(3).InfoS("No PostFilter plugins are registered, so no preemption will be performed")
} else {
// 这里面会执行抢占逻辑,什么是抢占呢?
// 相当于给 pod "开后门", 即如果 pod 的优先值比较高,删除一个比他优先级低的 pod(victim)。
// 然后返回 pod 抢占到的节点
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
...
...
// 构建提名信息
if result != nil {
nominatingInfo = result.NominatingInfo
}
...
...
// 这里面就是执行调度失败的逻辑, 会把 抢占者pod 加入到 unschedulableQ 队列中, 重新调度
sched.recordSchedulingFailure(fwk, podInfo, err, reason, nominatingInfo)
return
}
}
}
...
.
// 这就是我们说的 乐观假设,通过本地化数据模拟调度成功。最终结果就是 pod.Spec.NodeName = SuggestedHost
// 经过 filter 和 score 就开始模拟调度了
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
if err != nil {
...
// 这里就没有抢占,重新调度。
// 看到 "clearNominatedNode"没, 直接删除提名信息
sched.recordSchedulingFailure(fwk, assumedPodInfo, err, SchedulerError, clearNominatedNode)
return
}
// 即有时候会为 pod 预留一些资源比如 pvc(在 PreFilter 中也只会调用VolumeBinding,这时候就预留了pvc与 pv 的绑定逻辑, 放在上下文 CycleState 中的)
// default-scheduler 底层 只有一个 VolumeBinding 插件。所以这里也是操作本地缓存将 pvc 与 pv 的绑定。
if sts := fwk.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
...
...
sched.recordSchedulingFailure(fwk, assumedPodInfo, sts.AsError(), SchedulerError, clearNominatedNode)
return
}
// 这里会遇到"检查点" Permit。
// 有点尴尬的是 default-scheduler 里面没有实现 Permit插件。 所以可以不用管这块逻辑 所以注释掉
// runPermitStatus := fwk.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
// 最后就是通过异步协程的方式,向 apiserver 发送 pod 与 node 的绑定请求
go func() {
// 遇到绑定周期的 PreBind。
// 你看源码会发现跟调度周期中"检查点" Reserve 配置的插件是一样的,都是调用 VolumeBinding 插件实例。
// 就是做的 pvc 与 pv 的绑定
preBindStatus := fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
...
...
// 遇到 Bind "检查点"。
// 其实底层非常简单,就是给 apiserver 发送 v1.Binding 资源类型来完成真正的绑定。
sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)
...
...
// 最后会"检查点" PostBind。
// 但default-scheduler 里面也没有实现 PostBind插件。 所以也可以不用管这块逻辑
// fwk.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
}()
}
到这,一个调度周期的流程就讲完了, 总结一下流程如下:
- 拿到 pod
- 执行 filter 和 score 两大类 extend points (“检查点”)
- 这里如果执行失败,会发生抢占
- assume 模拟调度
- 执行 Reserve extend point (VolumeBinding plugins), 即在缓存中预绑定 pvc 与 pv。到这里绑定周期走完。
- 最后就是绑定周期
- PreBind extend point (VolumeBinding plugins):向 apiserver 发送 pvc 与 pv 的绑定
- Bind extend point 向 apiserver 发送 pod 与 node 的绑定
"检查点"
所谓"检查点"就是 extend points,上文也有介绍。
虽然 k8s 官方给出的是 Plugins 的概念,即调度策略可扩展的地方。
但个人更愿意把他们比作调度路上的"检查点",也确实像:每个"检查点"会有"多个不同的检察官"刁难,只要有一个地方返回 error, 整个调度就失败。
你可以在固定的点位(上文绿红黄箭标的地方),放置多个对应的"检察官"(plugins)。
我们来看看 "default-scheduler",默认放置了哪些:
// pkg/scheduler/apis/config/v1beta2/default_plugins.go
func getDefaultPlugins() *v1beta2.Plugins {
plugins := &v1beta2.Plugins{
QueueSort: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.PrioritySort},
},
},
PreFilter: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.NodeResourcesFit},
{Name: names.NodePorts},
{Name: names.VolumeRestrictions},
{Name: names.PodTopologySpread},
{Name: names.InterPodAffinity},
{Name: names.VolumeBinding},
{Name: names.NodeAffinity},
},
},
Filter: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.NodeUnschedulable},
{Name: names.NodeName},
{Name: names.TaintToleration},
{Name: names.NodeAffinity},
{Name: names.NodePorts},
{Name: names.NodeResourcesFit},
{Name: names.VolumeRestrictions},
{Name: names.EBSLimits},
{Name: names.GCEPDLimits},
{Name: names.NodeVolumeLimits},
{Name: names.AzureDiskLimits},
{Name: names.VolumeBinding},
{Name: names.VolumeZone},
{Name: names.PodTopologySpread},
{Name: names.InterPodAffinity},
},
},
PostFilter: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.DefaultPreemption},
},
},
PreScore: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.InterPodAffinity},
{Name: names.PodTopologySpread},
{Name: names.TaintToleration},
{Name: names.NodeAffinity},
},
},
Score: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.NodeResourcesBalancedAllocation, Weight: pointer.Int32Ptr(1)},
{Name: names.ImageLocality, Weight: pointer.Int32Ptr(1)},
{Name: names.InterPodAffinity, Weight: pointer.Int32Ptr(1)},
{Name: names.NodeResourcesFit, Weight: pointer.Int32Ptr(1)},
{Name: names.NodeAffinity, Weight: pointer.Int32Ptr(1)},
// Weight is doubled because:
// - This is a score coming from user preference.
// - It makes its signal comparable to NodeResourcesFit.LeastAllocated.
{Name: names.PodTopologySpread, Weight: pointer.Int32Ptr(2)},
{Name: names.TaintToleration, Weight: pointer.Int32Ptr(1)},
},
},
Reserve: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.VolumeBinding},
},
},
PreBind: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.VolumeBinding},
},
},
Bind: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.DefaultBinder},
},
},
}
applyFeatureGates(plugins)
return plugins
}
看到这,大家应该就很清晰每个扩展点(检查点)里具体的有哪些插件(检察官)。 而且也看到了, 这版里面调度周期并没有 "Normalize Score" 、 "Permit"; 绑定周期没有 "WaitOnPermit"、"PostBind" 这些 "检查点",也就是说假如我们可以跳过一些检查点。
"开后门"
所谓"开后门",就是如果 pod 有设置优先级,调度器会根据算法选出一个 node,将优先级比待调度pod 低的 pod(victim)都 "优雅"删除,然后将待调度的 pod.status.NominatedNodeName = 选出的 node。
概念的详情可以看官网的说明

这里我们来看看源码逻辑,发生抢占还是在 scheduleOne 中,调度流程一节中有提到:
func (sched *Scheduler) scheduleOne(ctx context.Context) {
...
...
// 执行完filter 和 score 逻辑
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, sched.Extenders, fwk, state, pod)
if err != nil {
// 提名信息
var nominatingInfo *framework.NominatingInfo
reason := v1.PodReasonUnschedulable
if fitError, ok := err.(*framework.FitError); ok {
...
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
if result != nil {
nominatingInfo = result.NominatingInfo
}
}
...
...
// 调度失败方法
sched.recordSchedulingFailure(fwk, podInfo, err, reason, nominatingInfo)
return
}
....
}
可以看到在执行 filter 和 score 的所有"检查点"后, 如果没有找到合适的 node,就要去执行抢占,即调用 PostFilterPlugins,也就是在 "Extension points" 一节中出现的红色箭标。
我们通过跳转来到抢占的源码逻辑,这里我们还是只关注流程:
func (ev *Evaluator) Preempt(ctx context.Context, pod *v1.Pod, m framework.NodeToStatusMap) (*framework.PostFilterResult, *framework.Status) {
...
...
// 1. 验证是否需要发生抢占,如果有 pod 已经处于删除中,就可以不用发生抢占
if !ev.PodEligibleToPreemptOthers(pod, m[pod.Status.NominatedNodeName]) {
return nil, framework.NewStatus(framework.Unschedulable)
}
// 2. 找到所有可以抢占的 node 以及他上面的可以被抢占的pod(我们统一将这类 pod 称为 victim)
candidates, nodeToStatusMap, err := ev.findCandidates(ctx, pod, m)
if err != nil && len(candidates) == 0 {
return nil, framework.AsStatus(err)
}
// 3. 通过 extenders 在过滤一次
candidates, status := ev.callExtenders(pod, candidates)
// 4. 找到最合适的
bestCandidate := ev.SelectCandidate(candidates)
if bestCandidate == nil || len(bestCandidate.Name()) == 0 {
return nil, framework.NewStatus(framework.Unschedulable)
}
// 5. 删除 victim, 再清除节点上比抢占 pod 优先级低的pod的提名(pod.Status.NominatedNodeName = "")
if status := ev.prepareCandidate(bestCandidate, pod, ev.PluginName); !status.IsSuccess() {
return nil, status
}
}
其实整体逻辑是比较清晰简单了。
然后我们再回到 scheduleOne 中 的 sched.recordSchedulingFailure(fwk, podInfo, err, reason, nominatingInfo) 方法中:
func (sched *Scheduler) recordSchedulingFailure(fwk framework.Framework, podInfo *framework.QueuedPodInfo, err error, reason string, nominatingInfo *framework.NominatingInfo) {
// 通过这里将被抢占的 pod 添加到 unschedulableQ 中。(不要被他 Error 迷惑了, 以为是个错误日志 -_-!!!)
sched.Error(podInfo, err)
if sched.SchedulingQueue != nil {
// 增加提名信息
sched.SchedulingQueue.AddNominatedPod(podInfo.PodInfo, nominatingInfo)
}
...
...
// 更新 pod status 中的提名: pod.Status.NominatedNodeName = nominatingInfo.NominatedNodeName
if err := updatePod(sched.client, pod, &v1.PodCondition{
Type: v1.PodScheduled,
Status: v1.ConditionFalse,
Reason: reason,
Message: err.Error(),
}, nominatingInfo); err != nil {
klog.ErrorS(err, "Error updating pod", "pod", klog.KObj(pod))
}
}
我们前面说过 unschedulableQ 中的 pod 会被转移到 activeQ 中重新调度。
所以到这里抢占 pod 的调度就结束了。
总结
一个 pod 的调度流程总结起来还是比较简单:
就是走完"调度周期" 和 "绑定周期"的Extends Points,整个调度周期是在本地模拟的。同时如果调度失败,可能会发生抢占其他pod的可能。这里总结成3点:
- 调度前通过本地缓存的 node 和 pod 信息,如果有 pvc 还会涉及到 pvc 和 pv 的缓存信息,来模拟调度
- 完整的调度分为 "调度周期" 以及 "绑定周期",每个周期中都有各自的 Extends Points(检查点)。我们可以硬编码的方式,添加自己编写的 Extends Points Plugins(我们前面说的检察官),来扩展调度功能。
- 在某节点抢占优先级低的 pod







