excel使用正则表达式提取文字的教程
相比于在python中使用正则表达式进行内容提取,在excel中学习与使用正则表达式更贴近生活工作内容、门槛更低。起码节省了安装工具的时间。
需求描述
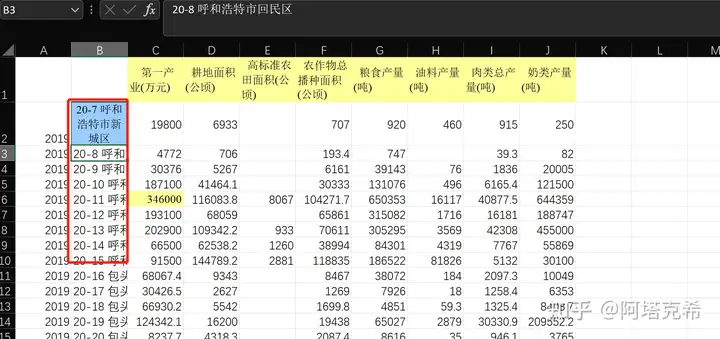
大概有二十个这样的表格,需要把每个表格B列中的文字部分提取出来。
如果不嫌麻烦,可以用excel中的函数手动提取指定字符数,然后大概很多遍也能做出来。
但是与其做枯燥重复的工作,不如做有一些创造性的。
正则表达式概述
正则表达式是一种字符串的匹配模式,全名为regular expression,简称为re。举个简单的应用例子,注册账号的时候要我们输入邮箱,网站会判断是不是规范的邮箱地址,这个过程中用到的就是正则表达式。包括识别你账号密码安全度时是否包含的大小写特殊字符等。
在excel中使用正则表达式
1.引入模块
首先需要引入正则表达式的模块,vba中的不会自带正则表达式模块的。当然引入也很简单,就是一句话的事,相当于python中的调包。
Set re = CreateObject("vbscript.regexp")2.初始设置
接下来在匹配之前进行简单的预设置。
re.Global = True
re.Pattern = "[^\u4e00-\u9fa5]"re.global=True
如果要保留匹配到的多个对象就填True,只保留第一个就是False 。
re.pattern就是匹配的具体模式了。
正则表达式的关键就在如何写才能得到想要的内容。
[\u4e00-\u9fa5]表示所有的中文字符
在前面加一个^表示除了中文字符都能符合匹配规则。
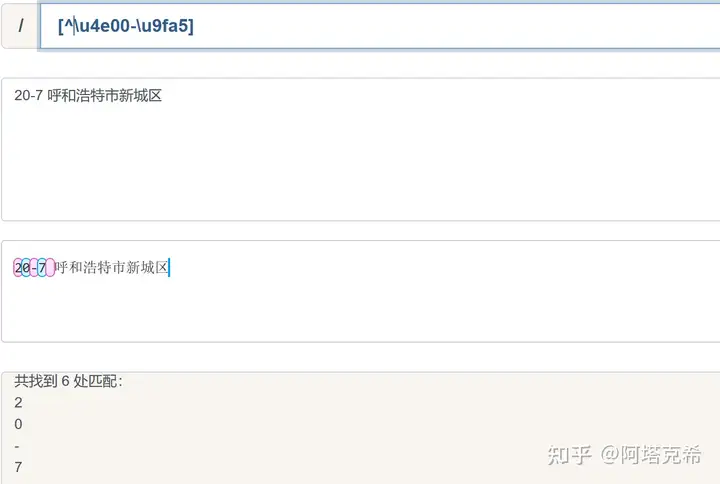
在测试中可以发现,能够符合要求。所以可以进行下一步了。
3.循环操作
首先要遍历所有的sheet,使用for each循环非常合适
for each i in sheets
.....
next由于每张表格的行数不一定相同,为了提高程序的稳健性,对每个sheet单独判断末尾行数
row_num = i.Range("B" & Rows.Count).End(xlUp).Row接下来就对sheet中单元格的遍历
For j = 2 To row_num
...
next最后是正则的具体使用
Set re_res = re.Execute(i.Range("b" & j))
're_res是一个匹配好之后的数组,里面是匹配到的元素的集合
i.Range("b" & j) = re.Replace(i.Range("b" & j), "")其实在这个例子中,第一个语句没啥用,写着玩的。真正有用的是第二句
因为这个例子的思路是匹配除了中文以外的所有字符,并用空字符代替,这样就只剩下中文字符了。
完整代码
Sub tiqu()
Dim i, re, row_num
Set re = CreateObject("vbscript.regexp")
re.Global = True
re.Pattern = "[^\u4e00-\u9fa5]"
For Each i In Sheets
row_num = i.Range("B" & Rows.Count).End(xlUp).Row
For j = 2 To row_num
Set re_res = re.Execute(i.Range("b" & j))
i.Range("b" & j) = re.Replace(i.Range("b" & j), "")
Next
Next
End Sub总结
如果说excel中的文本函数是牛刀,那正则表达式就是瑞士军刀。各有各的适用范围,使用文本函数能解决的情况下使用正则就是劳民伤财。
正则的难点在于能够写出正确的表达式,相比于这个,其他的正则操作难度就是相形见绌。







