谷歌多模态人工智能Gemini的一切
谷歌的Gemini是人工智能发展中的一个重要里程碑,标志着从单模态系统向更复杂的多模态模型的转变。
译自Gemini: All You Need to Know about Google’s Multimodal AI,作者 Janakiram MSV。
2022年12月6日,谷歌推出了Gemini,这是一款具有突破性的多模态AI模型,它可以处理和组合各种数据类型——如文本、代码、音频、图片和视频。Gemini有三种变体(Ultra、Pro和Nano)可供选择,适用于各种应用场景,从复杂的数据中心操作到设备上的任务,如Pixel 8 Pro和三星最新推出的Galaxy S24智能手机。Gemini在谷歌产品组合中的部署——包括搜索、Duet AI和Bard——旨在通过精细的AI功能增强用户体验,以其在理解自然图像、音频、视频和数学推理方面的最先进性能,为多模态AI模型树立了新的标准。
Gemini的开发是AI演进中的一个重要里程碑,标志着从单模态系统向能同时处理各种数据输入的更复杂多模态模型的转变。Gemini的transformer解码器架构和在各种数据集上的训练使其能够有效地集成和解释不同的数据类型,展示了谷歌在AI创新的承诺及其对未来AI应用的影响。
本文全面概述了Gemini及其能力。
Gemini架构的核心是基于transformer的结构,这是一种深度学习模型,颠覆了机器理解人类语言的方式。这种架构使Gemini在需要跨模态进行复杂推理和理解的任务中表现出色。
Gemini有三种变体:
Gemini 1.0 Ultra: 最大且最强大的模型,在复杂任务中表现卓越。它具有基于transformer的架构,正在进行广泛的测试和完善,然后再进行更广泛的发布。目前处于面向开发者的私有测试阶段,谷歌正在进行广泛的信任与安全检查,包括由外部方进行的红队行动,并通过来自人类反馈的微调和强化学习来完善模型。消费者可以通过Bard的最新版本Gemini Advanced体验Gemini Ultra。
Gemini 1.0 Pro: 性能和效率的平衡,面向开发者和企业开放,支持跨180多个国家/地区的38种语言,可以通过谷歌AI Studio中的Gemini API或谷歌云Vertex AI访问,在限制范围内免费使用,未来计划实行具有竞争力的定价。这是面向开发者公开的模型,用于构建由多模态变体Gemini Pro Vision驱动的聊天机器人或应用程序。
Gemini 1.5 Pro: 最近宣布的新一代AI模型,在用于开发大型语言模型(LLM)的87%的基准测试中优于其前身Gemini 1.0 Pro。它可以在长文本块中以99%的惊人成功率找到特定信息。Gemini 1.5 Pro在长上下文理解方面引入了突破性的实验性功能,具有标准的128,000个标记的上下文窗口,可以扩展到100万个标记。此外,Gemini 1.5 Pro展示了高水平的“上下文内学习”技能,使其可以从冗长的提示中学习新信息,而无需额外微调。该模型的上下文窗口容量也可达到100万个标记,使其可以一次性处理大量信息——包括视频、音频和大型代码库。此外,它可以无缝地分析、分类和总结提示中给定的大量内容,展示了其复杂的推理和理解能力。这个模型尚未向开发者公开。
Gemini 1.0 Nano: 最高效的,针对设备上的任务进行了优化,集成在Pixel 8 Pro智能手机中,为录音机应用中的“总结”和Gboard中的“智能回复”等功能提供支持,可以独立于互联网连接运行,增强数据隐私和安全性,并提高电池寿命。这在面向构建基于Android的移动应用的开发者中进行私有预览。Gemini Nano最终有望在资源有限的边缘设备上运行。
Gemini的多模态能力是其设计的基石,使其可以跨文本、图像、音频和视频理解和生成内容。这得益于其架构,其中包括用于图像生成的离散图像标记,并集成了通用语音模型的音频特征以进行细微的音频理解。对于视频数据,Gemini将其视为与文本或音频输入交织的顺序图像,展示了其无缝处理复杂多模输入的能力。
以下是Gemini变体的简要总结:
尽管谷歌没有透露训练过程的细节,但用于训练Gemini的数据集与其功能一样多样,包括网页文档、书籍、代码、图像、音频和视频。这确保了模型可以理解和处理各种各样的内容,使其在应用中具有高度的通用性。例如,Gemini可以通过组合不同的模式来理解和生成输出,从而执行图像字幕、视觉问答、代码分析和生成以及文本摘要等任务。
Gemini作为高能力语言模型
虽然Gemini被称为最佳的多模态AI模型,但它在本质上是一个高能力的LLM。与其前身PaLM 2相比,谷歌通过结合适用于广泛应用的高级功能,显着扩展了模型的功能。
Gemini 1.0 Pro的突出特征之一是其令人印象深刻的32,000个标记的上下文窗口,这使其可以以高度连贯和相关的方式处理和生成长格式的内容。这个广泛的上下文窗口比之前的模型向前迈进了一大步,使Gemini能够在更长的对话或文档中保持上下文,从而增强其理解和生成细微且复杂内容的能力。
Gemini嵌入模型是谷歌Gemini AI的组成部分,旨在将文本转换为丰富的嵌入向量,捕获内容的语义细微差别。这些嵌入向量是可以用于各种应用的向量表示,如语义搜索、内容推荐和相似文本的聚类。嵌入模型支持最多30,720个输入标记和最多2,048个输出标记,使其能够处理大量文本数据。模型的请求速率限制高达每分钟1,500次请求,经过优化以实现性能和可扩展性,这使它成为开发人员在将先进的自然语言理解能力引入其应用时的有价值工具。
将Vertex AI搜索和对话服务与Gemini LLM和嵌入模型相结合,可以使开发人员构建先进的AI助手,具备问答、摘要和情感分析能力。
Gemini作为强大的多模态AI模型
Gemini Pro Vision是Gemini的一个先进变体,旨在在多模态理解和交互中拥有卓越表现。该模型能够处理和解释来自文本和视觉模式(包括图像和视频)的输入,以产生连贯的、情景适当的文本响应。
作为一个大型语言视觉模型的基础,Gemini Pro Vision在各种任务中表现出色。这些任务包括从视觉理解和分类到基于视觉输入的内容摘要和创作。该模型的能力不仅限于简单的文本和图像交互,而且扩展到对照片、文档、信息图表和屏幕截图进行复杂分析,展示了其在各种多模态应用中的多功能性和可扩展性。
我向Gemini Pro Vision提供了Charminar的图像以及提示:“识别这座建筑物、所在城市和最著名的美食”,它返回了正确的回答:Charminar、海德拉巴、Biryani。
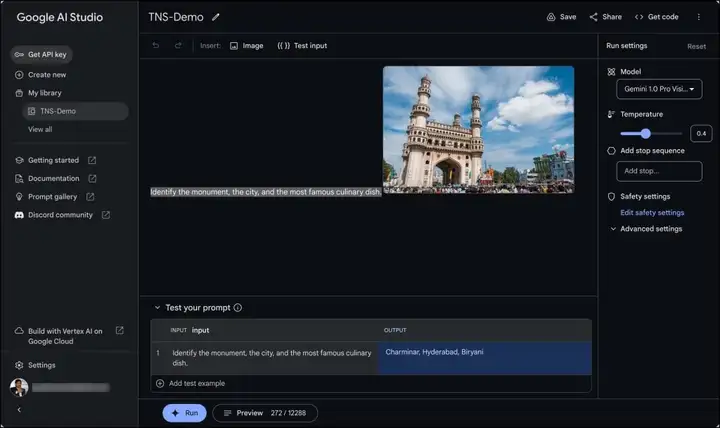
Gemini Pro Vision的技术实力在于其无缝整合和理解多模态提示的能力,从而实现了广泛的用例。开发人员可以利用这个模型将复杂的视觉理解集成到他们的应用程序中,解锁如下功能:
- 信息检索:将世界知识与视觉数据无缝结合,提升信息搜索能力。
- 物体识别:对视觉内容中的对象进行精确和详细的识别。
- 数字内容理解:从复杂的视觉内容中提取有价值的见解,包括图表和信息图表。
Gemini Pro Vision可以以HTML、CSV和JSON等格式生成针对提示的结构化内容,也可以从图像或视频中推断信息,对未见或后续的内容做出明智的猜测。这种广泛的功能突显了该模型在推进多模态AI领域的重要意义,为开发者提供了一个强大的工具来创建更直观和交互式的应用程序。
开发者如何开始使用Gemini?
开发者可以通过谷歌AI Studio或谷歌云Vertex AI访问Gemini Pro 1.0,而Gemini Ultra 1.0、Gemini Pro 1.5和Gemini Nano 1.0也可通过私有预览供特定用例使用。
谷歌AI Studio提供了一个基于Web的工具,用于原型设计和运行提示,而Vertex AI提供了一个更全面的平台来部署和管理AI模型,具有额外的安全性、隐私性和合规性功能。如果您正在开发和部署在谷歌云环境之外运行的应用程序,您可以在谷歌AI Studio内生成API密钥以访问这些模型。谷歌AI Studio也充当试验场,用于尝试各种提示和影响响应准确性的API参数。
Gemini Pro 1.0提供了一个大型的免费套餐,允许开发人员在没有初始成本的情况下构建生成式人工智能应用程序。免费套餐包括每分钟60个查询的速率限制,输入和输出都是免费的。按使用量付费的定价将很快推出,对于超出免费套餐限制的用户,将提供具有竞争力的价格。开发人员可以通过联系他们的谷歌账户代表来提前获得Gemini Ultra的访问权限。







