stable diffusion企业级教程:图生图Inpainting功能大揭秘!
聊一些偏理论设计的内容。具体而言,我们希望来聊聊,基于SD实现的不同功能中,模态之间的结合是怎样的。
比如,在基础的文生图应用中,我们知道文本信息和图像信息是通过cross-attention进行融合的,本质上可能就是若干层transformer,那么其中的qkv又是如何生成的?对于图生图功能,引入进来的图和又是如何来影响最终图像生成呢?而对于inpainting功能,为什么会有单独的inpainting模型?原始的模型又是如何实现inpainting功能的呢?
接下来,让我们深入代码,来看看文本和图像,是如何在sd中被神奇的结合在一起的。
2、TextToImage
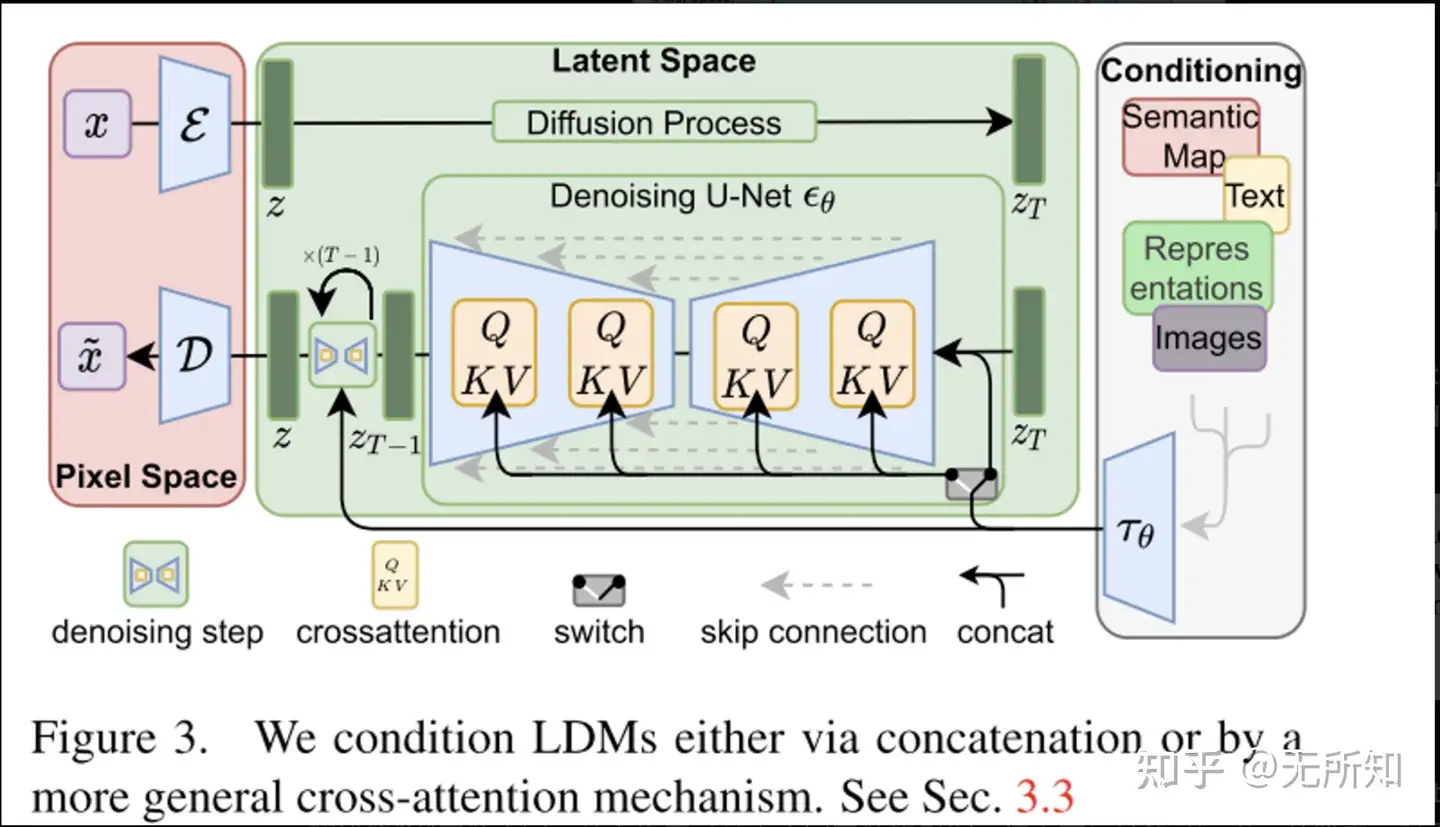
这个图相信大家已经很熟悉了,是摘自”High-Resolution Image Synthesis with Latent Diffusion Models ”的latent-diffusion原理示意图。也是依据这个原理,stable-diffusion才能够被成功的训练并且和大家见面。
论文中提到,文本向量和图片向量,是通过 “cross-attention”来进行融合的。”cross-attention“来自于”attention is all your need“这篇论文。虽然文章中没有明确提到,但是其中的”encoder-decoder attention“已经有了”cross-attention“的精髓——即,QKV的来源不同。

在原始的self-attention中,QKV都是通过原始输入与不同矩阵计算得到,而在”cross-attention“中,初始的”X“来源不同,从而生成了基于不同来源的QKV,进而在后续的attention计算中,对不同来源的”X“进行融合。
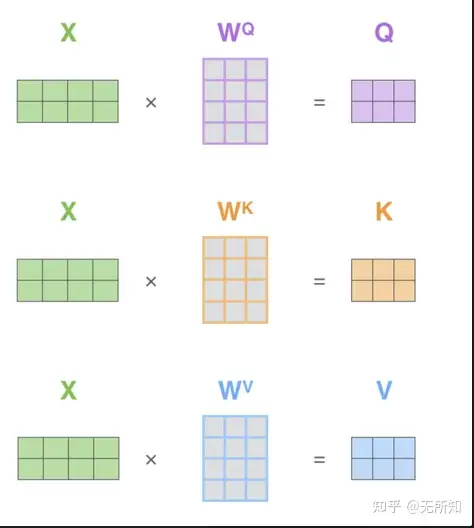
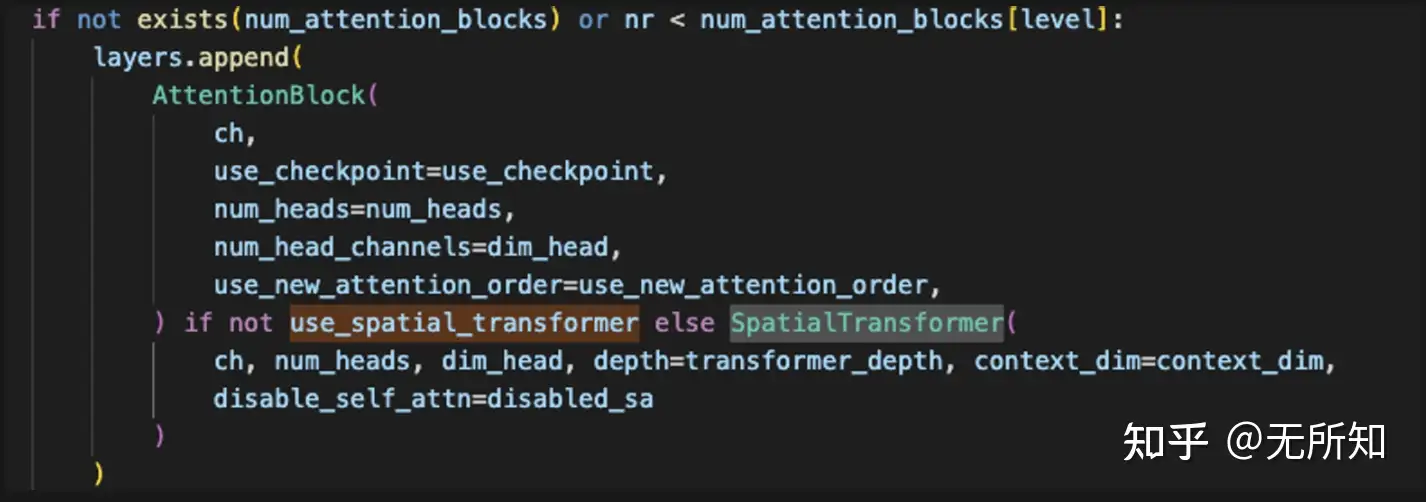
那在sd的case种,X主要就是两个来源,文本和图像。通过论文中我们知道,sd中的cross-attention发生在unet部分,那通过 pokemon.yaml 中unet部分的配置,可以定位到 ldm/modules/diffusionmodules/openaimodel.py中的 UNetModel 类。
在该类中,我们通过配置文件设定了 use_spatial_transformer 为True,因此在创建attention模块时,统一用的都是 SpatialTransformer 这个类。
在 SpatialTransformer 这个类中,我们发现它对于图像数据做了一个拉长,将(b,c,h,w)转换成(b,(hw),c)的张量,即将图像数据变成了一个长为hw,维度是c的sequence。
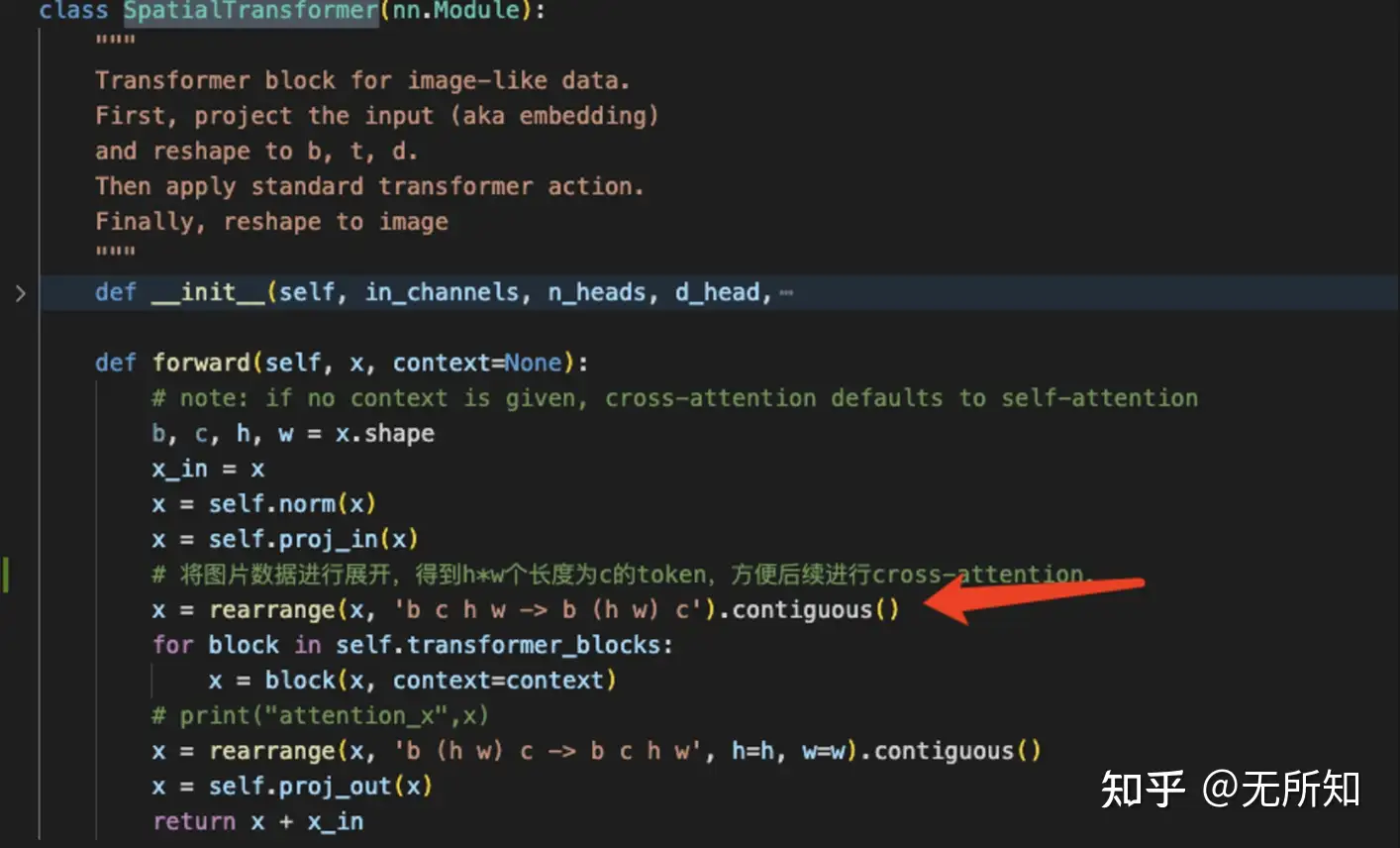
而在后续的 ldm/modules/attention.py/CrossAttention 类中,其通过图像转换的sequence来生成query,用文本的数据来生成key和value来进行cross-attention。
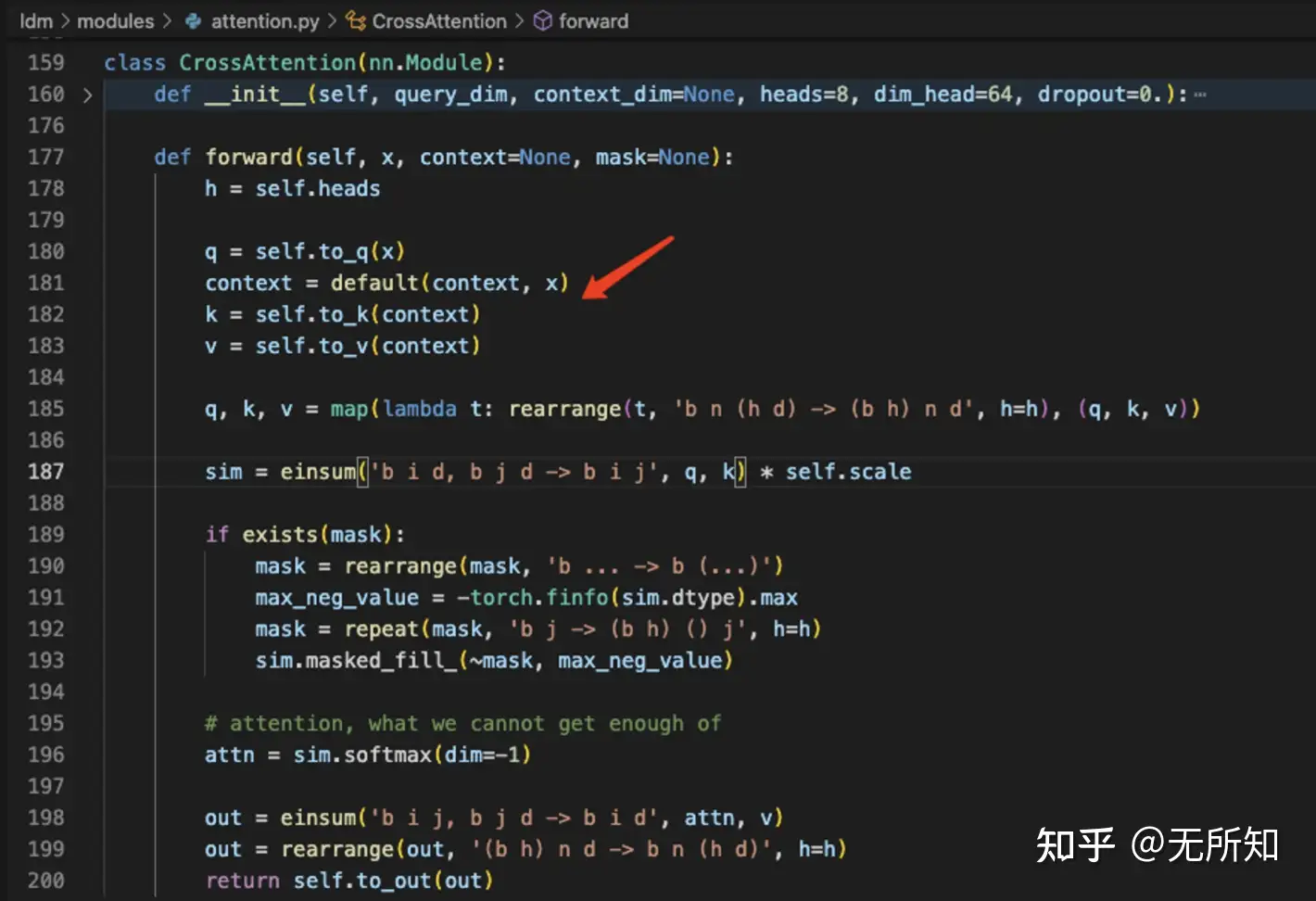
其实这个也是比较好理解,因为在训练SD的过程中,text-encoder部分是固定不更新的,那么自然就是让图像编码和文本编码靠拢,那么自然就是将text的embedding作为value,通过self-attention机制来生成新的,基于文本条件的图像信息。
那么对于后续的finetune,比如我们的中文encoder训练,是否可以考虑颠倒这里的关系,将q替换为文本特征,k和v替换成图像特征,让新加入的中文encoder向预训练的unet进行靠拢。这是一个值得考虑的方向~
3、ImageToImage
经常使用webui的同学应该对这个页面很熟悉了,我们利用这个页面,可以快速的视线图生图功能。即,将图片和文本同时作为sd生成时的参考,来引导最终图像的生成。
那除了在页面上,我们项目内部,可以通过 scripts/img2img.py 来体验相关的功能。那么在img2img这个功能上,图像是如何被引入来印象最终图像的生成呢?
这里我们需要聊一聊sd的基本原理,想全方位了解的可以看下面这个链接,我这里就简单阐述一下推理的过程。
在sd模型推理的时候,我们通过某种采样方式得到了一张全部为随机噪声的随机图像;根据当前处理的步数和当前的图像A,我们通过diffusion模型可以计算得到到一个图像B,模型认为,当我们把图像B从图像A中拿走后,剩下的图像会更贴近我们想要的效果,即A_new = A-B. 那不断地重复这个“预测B,拿走B”的过程,最终剩下的就是我们最终的预测图像。
那当用于SD预测的文本以及迭代次数都不变时,唯一会影响最终结果的因素就是初始这个随机图像,因此,可以一定程度上认为,当其他内容都确定时,最终图像的效果是由最初的噪声来确定的。
回到图生图的这个问题上来,为了能够让我们输入的图像来指导图像的生成,一个很直观的思路就是利用输入图像来生成这个噪声。具体的过程可以参考diffusion原理中给原图加K步噪声的过程,我这里就不赘述了。在代码里面,主要体现在下图标注的两个位置上。
位置1)是将原图转换成VQGAN的隐空间向量,因为diffusion过程都是在这个空间上进行的;
位置2)则是将隐空间向量进行加噪处理,使其变成随机噪声。
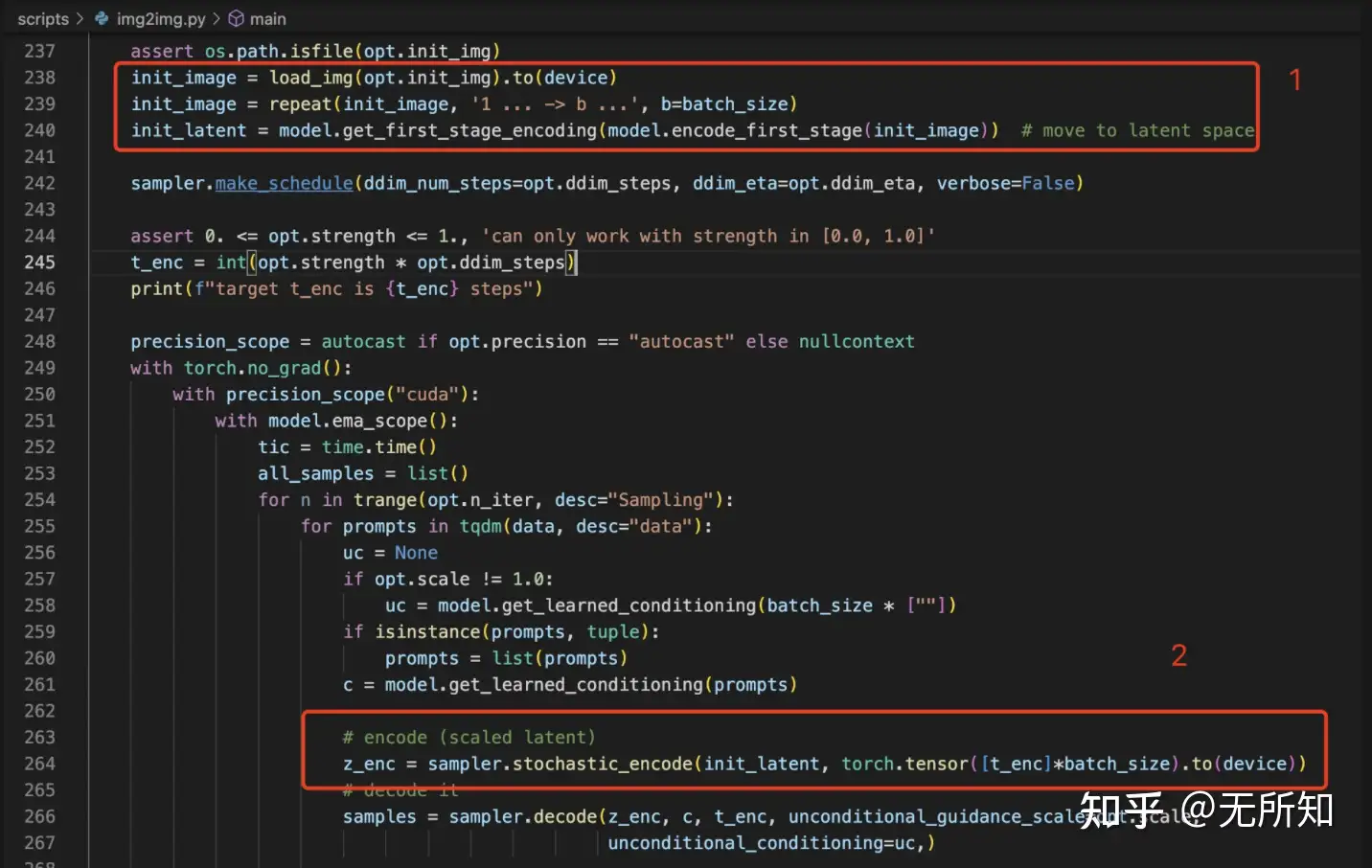
有兴趣的可以深入 decode 方法看看,会发现这里传入的 z_enc 变量,刚好替代了生成时需要随机生成的初始噪声。
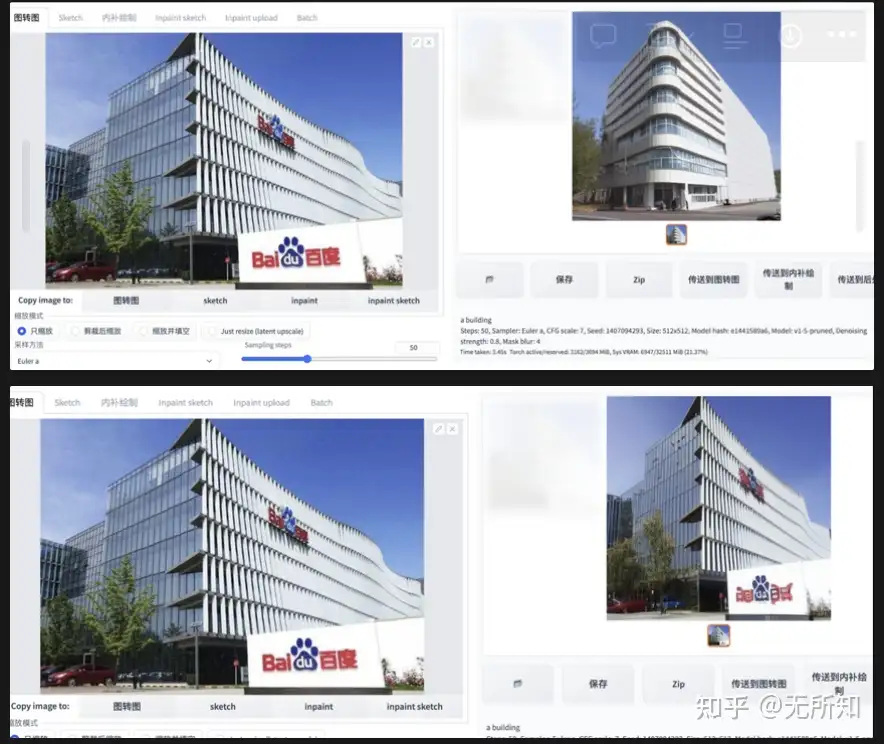
通过把输入图像和指导文本引入生成过程,我们可以更好的控制生成效果。比如在下图中,我希望生成一个建筑(a building),指导图像为百度大厦。从最终的结果可以看到,生成出来的建筑物在色调和角度上,都和指导图十分相似。
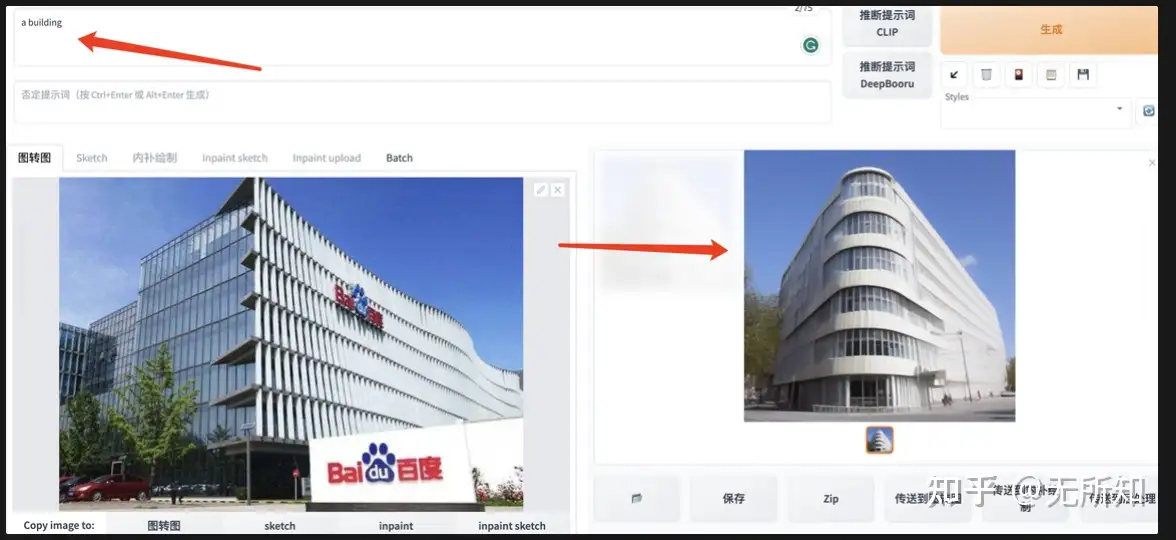
另外注意,这里控制生成图和输入图的相似程度,是通过两个参数来指定的:1)Sampling Steps ;2)降噪强度。
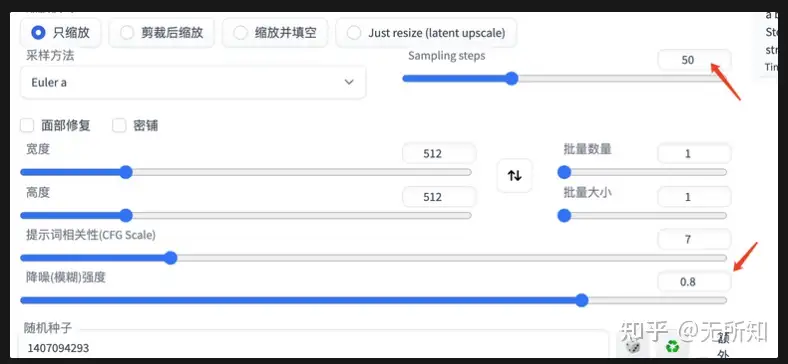
两者相乘即为最终的去噪步数。上面展示的是Sampling Steps 为20,降噪强度为0.8的结果;下图是Sampling Steps 为50,降噪强度为0.8的结果以及Sampling Steps 为50,降噪强度为0.2的结果
=======20230613补充=======
这段时间在Imagen上实现了图生图的功能,发现还有很多东西可以聊,这个图生图功能没有我们想象的那么简单。
首先,我们从配置文件中可以看到,训练的时候用的timesteps是1000,它表明两点:
1、我对一张原图加噪1000次,将其变为纯噪声;
2、我对一张噪声图去噪1000次,将其变为原图;
这里要注意,纯噪声和原图是这个轴上的两个端点,timesteps仅仅负责这部分进行切分,那么timestep的大小就只表明将部分切的多细,而不是说,timesteps越大,加噪越多或者成图越好。因此,当timesteps=1000,加噪500次,与timesteps=100,加噪50次,出来的噪声图是差不多的。
说这个timesteps,是为了更好的理解后面我们的生成过程。当生成的时候,我们选择生成步骤为20,那么会根据训练时定好的timestep=1000,从中选取20个点,使其覆盖这1000步。一个简单的方法就是选取[0,50,100,150,…,1000]作为这20个点,来进行去噪。这也一定程度上解释了为什么随机数固定时,不同的去噪步数,出图的效果都差不多。
那图生图又是怎么回事呢?前面说的确定初始的噪声,其实不是很明确,具体操作是这样的。同样以去噪步骤为20来举例,我们这里选择strength=0.2,那么就是希望最后出的图和原图比较接近。对于步骤为20,对应的加噪步骤强度为 [0,50,100…1000],1000表示纯噪声。那么这里,对于图生图而言,我们选取idx=20*0.2=4, 对应加噪步骤强度为150的强度对原图进行加噪,得到初始噪声。由于这个噪声是对应于于150的,那么自然不能从1000开始降噪,需要从150开始降。降噪强度分别是150,100,50,0,最终得到原图。这也就解释了,为什么图生图的过程中,当选择了strength时,迭代的步骤为 sampling_steps * strength .
图生图相当于是把图片按照一定比例进行加噪,并做去噪的起点,从扩散过程的中间开始,直至原图。
4、Inpainting
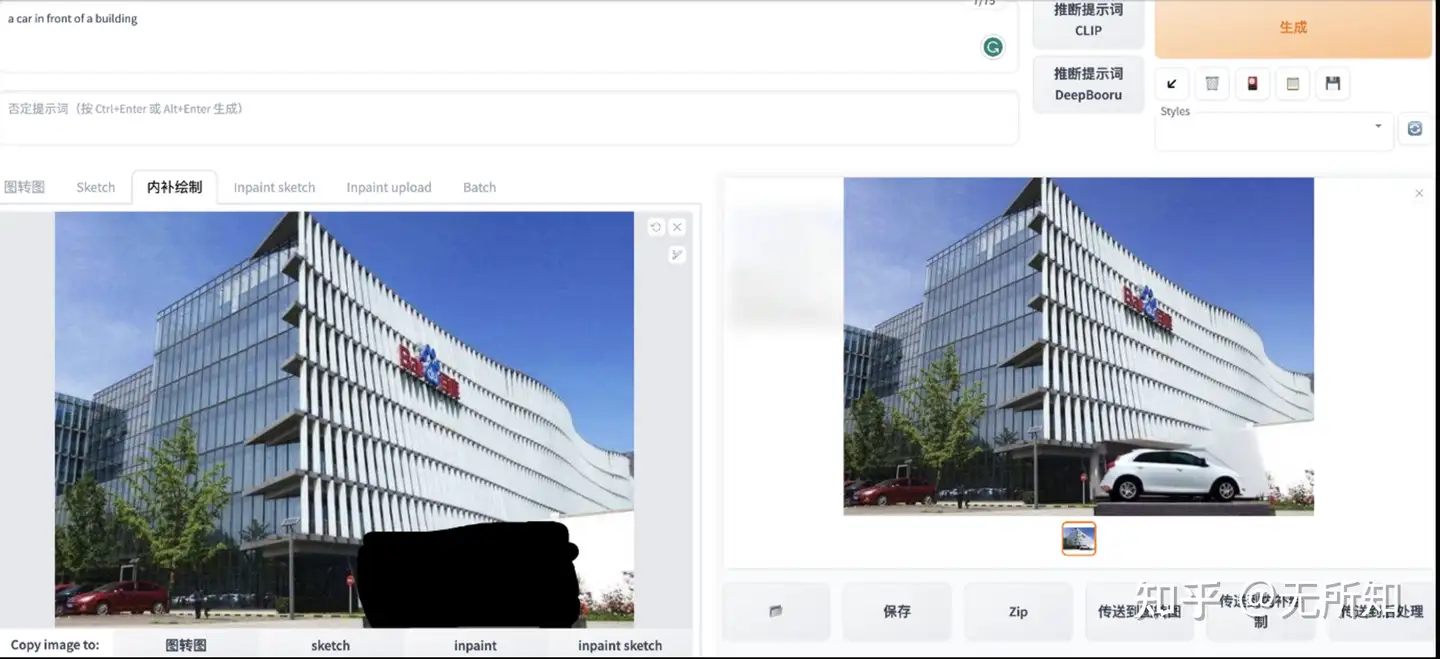
inpainting是一个很好玩也很有用的功能。它可以让我们在不影响图像其他区域的情况下,对自己所选的区域进行修改。
上图展示的是基于webui提供的inpainting功能。不过大家在使用该功能的时候,是否好奇,webui是怎么利用基础的sd模型来实现inpainting功能呢?
无论是runwayml,compvis还是stability,好像都是选择利用一个新的模型来提供inpainting功能,这和基于原始的sd来进行inpainting,究竟有什么差别呢?

4.1 inpainting with new model
这里我们来看看,专门用于inpainting功能的模型,是如何实现这个能力的。
首先,我们需要知道,在inpainting时,我们会有哪些数据。除了基本的文本内容,我们会有原始图像,mask图像,以及容易被忽略的masked-image。个人理解是与其让模型根据图片和mask自己去生成masked-image,不如人工给出,这样能够降低模型的计算压力。

其次,我们来看看inpainting 模型的配置文件 configs\stable-diffusion\inpaint\v1-finetune-for-inpainting-laion-iaesthe.yaml,会发现最主要的区别有两点,一方面是主要的模型从 LatentDiffusion 变成了 LatentInpaintDiffusion ;另一个更重的是,在unet部分(也就是diffusion model部分),输入图像的维度从4变成9.
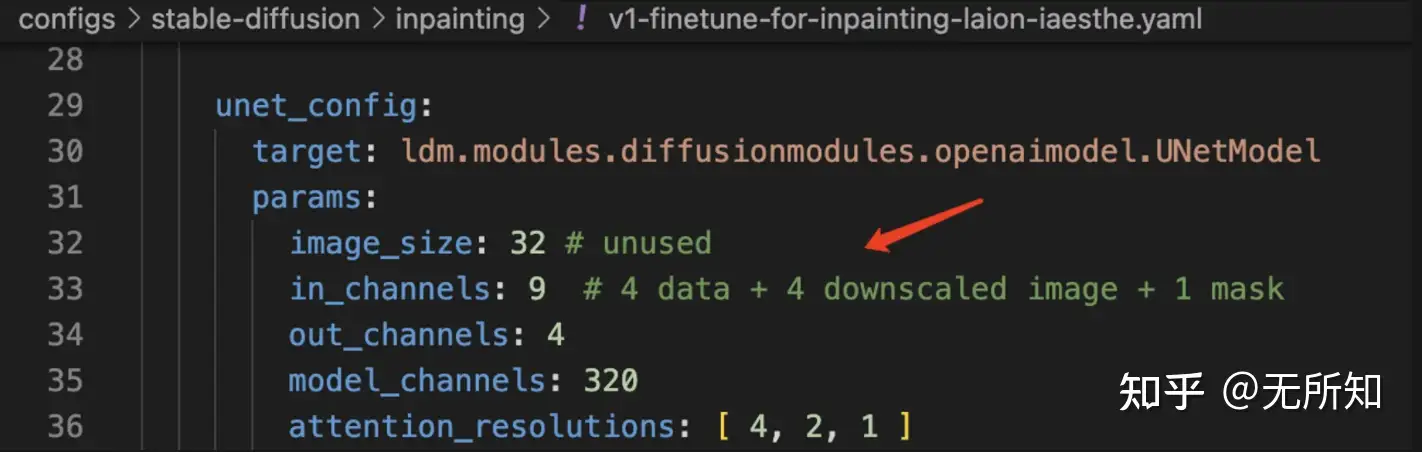
LatentInpaintDiffusion 影响的是数据的处理,这里会增加额外的处理逻辑,帮助我们利用字典组织好需要被不同对待的条件信息(比如文本的特征放在”crossattn“下面,而在”concat“下面就放一些需要被拼接的条件);而 unet 部分新增的5个channel,则刚好对应上文提到的两个mask相关数据:mask(1 channel)和masked-image(4 channel)。
那么关键在于如何在迭代中将这两个新增的条件给用起来,从而达到”仅修改mask区域,且与原图很好的融合“这一目标。
那在new-model这里就非常简单,预处理将mask 和 mask-image转换成 VQGAN空间的张量后,仅仅是在每次迭代时,将这两个张量与等待去噪的输入噪声向量进行concat,并一起送入diffusion模型进行预测,得到相关的预测结果。
具体的代码流程可以参考这几个文件和方法:
- 1)原始数据处理:
scripts/inpaint_sd.py⇒make_batch_sd - 2)VQGAN张量映射:
ldm/models/diffusion/ddpm.py⇒LatentInpaintDiffusion.get_input() - 3)和噪声张量concat:
ldm/models/diffusion/ddpm.py⇒DiffusionWrapper.forward
这样”偷懒“的行为其实会让模型,除了需要学习如何处理多出来数据同时,也需要对其之前掌握的绘画能力进行重新调整。因此可以看到,在runwayml的repo中提到, sd-v1-5-inpaint.ckpt 是在 sd-v1-5.ckpt 的基础上,又训练了440K个step得到。要知道,作为base模型的sd-v1-5.ckpt ,也就训练了595K个step。
4.2 inpainting with base model
ok,接下来就是看看神奇的webui是如何利用basemodel来实现这个功能的。
注意inpainting功能有两点需求:
- 1)仅对mask区域进行修改,不改变mask区域之外的内容
- 2)生成的结果和其他区域尽可能和谐;
这里参考的代码是这一份,相比大家也都很熟悉了~
这里我们参考DDIM-Sampler下,webui对inpaint的实现。同样,我们有原图 img_org,mask,以及文内内容text,它的inpainting步骤如下:
- 1)将img_org映射到VQGAN隐空间,得到
init_latent; - 2)初始化随机噪声
x_dec; - 3)对于每一次迭代(每个时间步),执行:
- 基于时间步t,生成
init_latent对应的加噪声数据img_noise_t - 此时我们有两个噪声,一个是基于上个时间步降噪后得到的张量
x_dec,一个是基于原图得到的张量img_noise_t.此时我们通过mask将两者融合,有x_dec_new = mask * img_noise_t + (1-mask) * x_dec即,将原图中的非mask区域和噪声图中的mask区域进行融合,得到新的噪声图。 - 送入后续的 diffusion 网络进行去噪。
- 循环直到结束。
- 基于时间步t,生成
详细的,基于DDIM-Sampler的视线可以参考webui中的这个方法。modules/sd_samplers_compvis.py
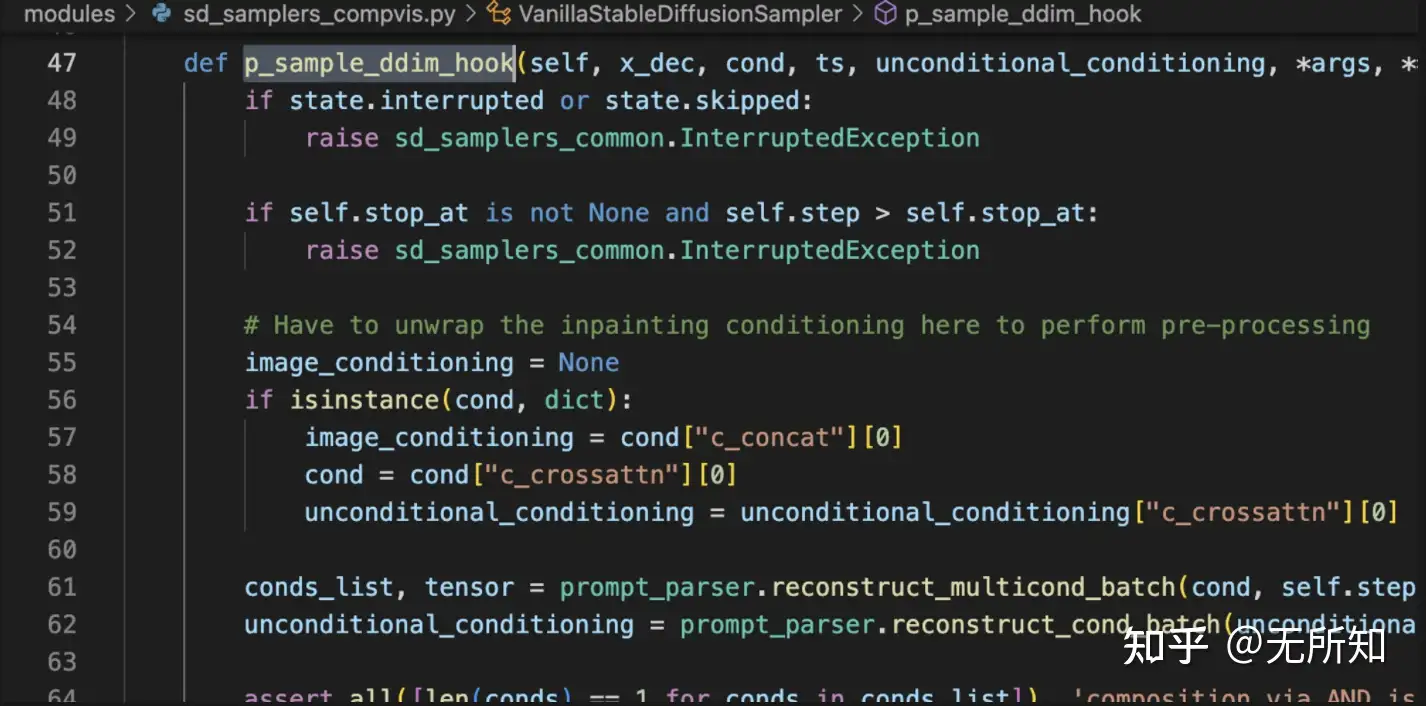
4.3 inpainting 补充说明
上面提到了webui中的inpainting方法,这里也仔细聊聊它的几个配置项。
- 1)mask-mode:这个很好理解,就是你需要重绘被遮盖区域还是未遮盖区域。实现时,无非就是根据输入对mask取反即可。

- 2)masked-content/蒙版蒙住的内容:这个对应于webui代码中,
modules/processing.py中,StableDiffusionProcessingImg2Img类的self.npainting_fill成员变量。简单理解,这个选项控制了基于原图的init_latent的生成方法(4.2中也提到了)。- 填空:用于原图模糊后的数据进行填入
- 原图:直接用原图填入
- latent noise: 随机噪声
- latent nothing:全零
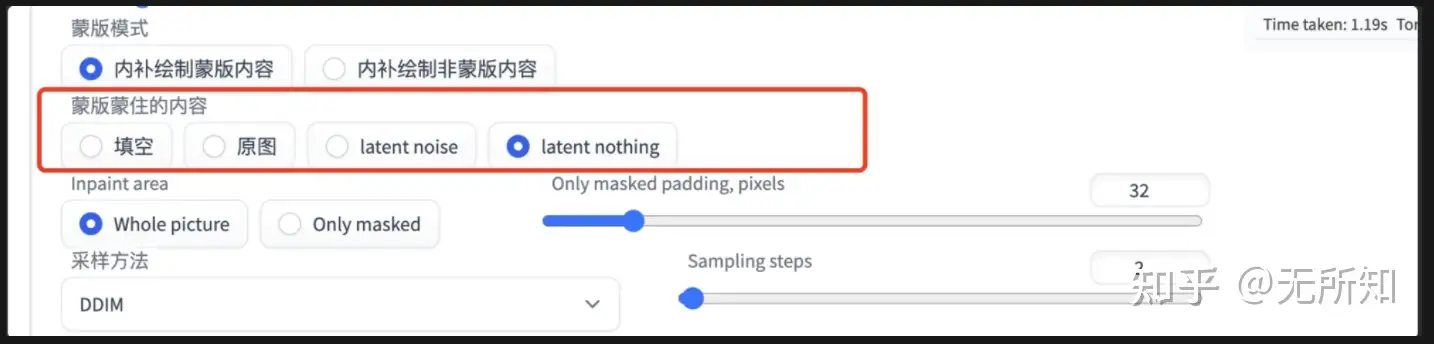
- 3)inpaint area/重绘区域:这个对应于webui代码中,
modules/processing.py中,StableDiffusionProcessingImg2Img类的self.inpaint_full_res成员变量。简单理解就是指定我需要送入模型初始图区域,是整张图还是mask附近的区域。- whole picture:全图送入,那么就对原图和mask按照指定的size进行resize即可
- only mask: 在mask周边做裁剪,将裁剪后的图按照指定size进行resiz后,进行重绘,重绘完成后再和原图合并。

5、总结
本篇文章主要是一个理论的总结,梳理了sd模型以及基于sd模型的webui,是如何实现文生图,图生图以及inpainting的功能。
里面提到的模态融合是一个很关键的能力,深度学习皇冠上的下一颗钻石说不定就是它(笑)。另外这里会需要对diffusion模型本身有一定理解,不是数学层面,而是站在模型结构层面,这方面有需要的小伙伴可以看看参考中的第四个链接 “the illustrated stable diffusion”。







