ComfyUI实现InstantID功能:一张照片生成各种风格的个性化图像
2024年的AI绘画主要是卷细节,卷角色一致性,继续分享做到角色一致性的AI绘画工具,InstantID。

项目报告地址:https://arxiv.org/pdf/2401.07519.pdf
项目演示地址:https://instantid.github.io/
项目代码地址:https://github.com/InstantID/InstantID
项目demo地址:https://huggingface.co/spaces/InstantX/InstantID
一、InstantID概述
使用文本反转、DreamBooth 和 LoRA 等方法在个性化图像合成方面取得了重大进展。然而,它们在现实世界中的适用性受到高存储需求、冗长的微调过程以及对多个参考图像的需求的阻碍。
相反,现有的基于ID嵌入的方法虽然只需要一次前向推理,但面临着挑战:它们要么需要对众多模型参数进行广泛的微调,要么缺乏与社区预训练模型的兼容性,要么无法保持高人脸保真度。
为了解决这些局限性,推出了 InstantID,这是一种强大的基于扩散模型的解决方案。
即插即用模块只需使用一张面部图像即可熟练地处理各种风格的图像个性化,同时确保高保真度。为了实现这一点,设计了一种新颖的身份网,通过施加强语义和弱空间条件,将面部和地标图像与文本提示相结合,以引导图像生成。
InstantID 表现出卓越的性能和效率,在身份保存至关重要的实际应用中证明非常有益。此外,与流行的预训练文本到图像扩散模型(如 SD1.5 和 SDXL)无缝集成,作为适应性强的插件。
二、InstantID的框架和主要技术细节
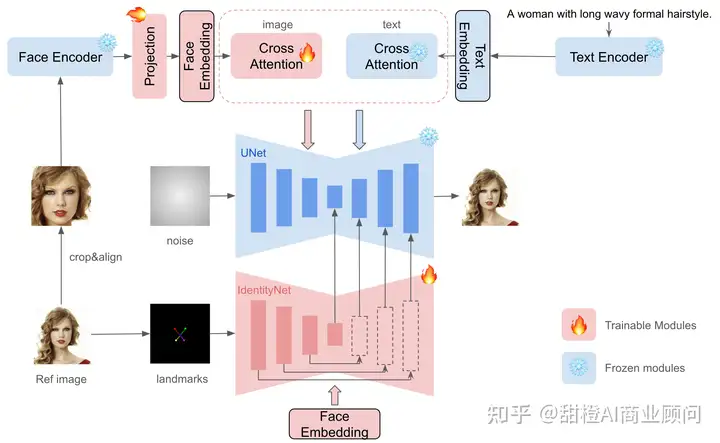
1、ID嵌入(ID Embedding):
InstantID使用预训练的面部模型来检测和提取参考面部图像中的面部ID嵌入。这些嵌入包含了丰富的语义信息,如身份、年龄和性别等,这对于精确保持身份至关重要。
与CLIP图像嵌入相比,ID嵌入提供了更强的语义细节和更高的保真度,这对于身份保持任务尤为重要。
2、图像适配器(Image Adapter):
InstantID引入了一个轻量级的适配模块,该模块具有解耦的交叉注意力机制,允许图像作为视觉提示与文本提示并行使用。
这个模块通过额外的交叉注意力层嵌入图像特征,同时保持其他参数不变,从而增强了文本提示的能力,尤其是在描述难以用文本表达的内容时。
3、IdentityNet:
IdentityNet是InstantID的核心组件,它负责编码参考面部图像的详细特征,并提供额外的空间控制。
在IdentityNet中,生成过程完全由面部嵌入引导,不涉及任何文本信息。这使得网络能够专注于与身份相关的表示,而不受到面部和背景描述的一般性描述的影响。
4、训练和推理策略:
在训练过程中,InstantID只优化图像适配器和IdentityNet的参数,而保持预训练的文本到图像扩散模型的参数不变。
使用类似于原始稳定扩散工作的训练目标,但增加了一个特定的图像条件Ci,用于IdentityNet。
在推理过程中,InstantID能够仅通过单张参考图像生成具有各种姿势或风格的定制化图像,同时确保高保真度。
三、InstantID的主要功能

InstantID的主要功能集中在实现零样本(zero-shot)身份保持的图像生成,具体包括以下几个方面:
1、身份保持图像生成:
InstantID能够使用单张面部图像作为参考,生成保持该图像中人物身份特征的新图像。这包括但不限于面部表情、年龄、性别等身份细节的精确复制。
2、风格和姿势变化:
在保持身份特征的同时,InstantID允许用户通过文本提示改变生成图像的风格和人物姿势,例如改变服装、发型或背景。
3、空间控制:
InstantID与预训练的空间控制模型(如ControlNet)兼容,这意味着用户可以引入额外的空间控制信息(如草图、深度图等),以进一步精细化生成过程。
4、多身份和多风格合成:
InstantID能够处理涉及多个角色和风格的复杂场景,实现多身份合成,即在一张图像中融合多个人物的特征。
5、新视角合成:
InstantID可以用于创建新视角的合成图像,即使原始参考图像没有提供该视角的信息。

6、身份插值:
InstantID能够实现不同身份特征之间的平滑过渡,例如在两个不同人物之间进行特征插值。
7、插件兼容性:
InstantID作为一个插件,可以无缝集成到现有的预训练文本到图像扩散模型中,如SD1.5和SDXL,而无需对这些模型进行额外的训练。
8、无需微调:
InstantID的设计使其在推理阶段不需要进行微调,这大大提高了生成过程的效率和实用性。
9、代码和资源开放:
InstantID提供了开源的代码和预训练模型,使得研究者和开发者可以轻松地访问和利用这项技术。

四、InstantID的主要实验结果
1、定性结果:
图像仅模式(Image Only):在没有文本提示的情况下,InstantID能够仅依赖参考图像生成具有丰富语义内容的图像,如表情、年龄和身份。实验结果显示,即使在没有性别提示的情况下,生成的图像也能较好地保持这些特征。
图像+提示模式(Image + Prompt):通过结合文本提示,InstantID能够在保持身份一致性的同时,有效地改变性别、服装和发色等特征。
图像+提示+空间控制模式(Image + Prompt + Spatial Control):InstantID与预训练的空间控制模型(如ControlNet)兼容,能够引入灵活的空间控制,如边缘检测(canny)和深度信息,进一步增强生成图像的细节。
2、消融研究:
实验评估了InstantID内部模块的有效性,特别是ID嵌入和IdentityNet对生成结果的影响。结果表明,IdentityNet单独使用时已经能够实现良好的身份保留,而图像适配器的加入进一步增强了面部细节的恢复。
3、与现有方法的比较:
与IP-Adapters的比较:InstantID与现有的IP-Adapters(如IP-Adapter-SDXL、IP-Adapter-SDXL-FaceID和IP-Adapter-SDXL-FaceID-Plus)进行了比较。结果表明,InstantID在保持身份的同时,能够更有效地融合面部与背景风格,且在单张参考图像的情况下也能取得与多参考图像训练的LoRAs相媲美的结果。
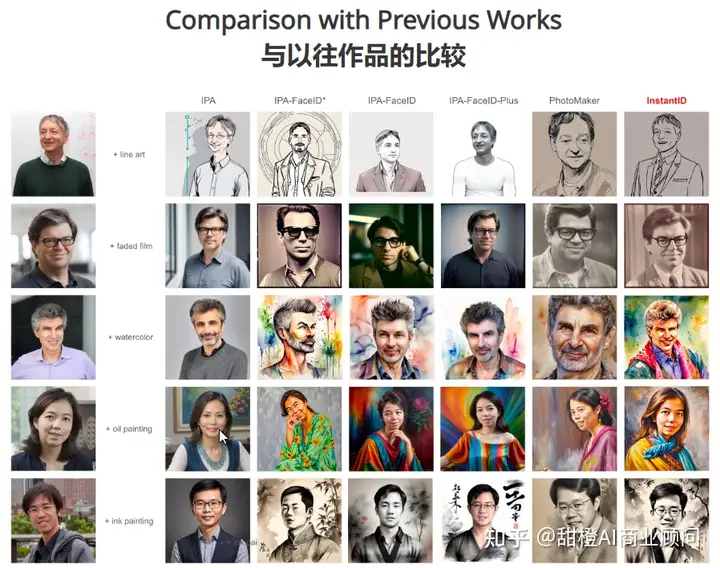
与LoRAs的比较:InstantID与使用多张参考图像训练的LoRA模型进行了比较。尽管LoRA模型通常需要大量的数据和训练,InstantID仅使用单张图像就能达到竞争性的结果,展示了其在效率和实用性方面的优势。

4、应用场景:
新视角合成:InstantID能够生成新视角的图像,同时保持角色的一致性。
身份插值:展示了InstantID在不同角色之间进行特征插值的能力,实现了平滑的身份过渡。
多身份合成:InstantID能够处理包含多个角色的复杂场景,展示了其在多角色合成方面的潜力。


五、ComfyUI 的 InstantID 的非官方实现

项目代码地址:https://github.com/ZHO-ZHO-ZHO/ComfyUI-InstantID?tab=readme-ov-file







